Introduction
We all interact with a variety of digital products in our daily lives. But have you ever thought how these products offer such phenomenal experiences that make our lives so easy and convenient?
Netflix let’s say, knows exactly what shows to recommend. Amazon suggests products you didn’t even know you wanted. Take Fitbit, how does it transform your steps into a comprehensive health profile? Or consider Google Maps, it not only tells you the fastest route but also predicts traffic jams before they happen.
The one thing common in these high personalized experiences is that they are powered by high quality data. Data ingested from our interactions with devices feed into advanced AI/ML models in real time which helps uncover needs, preferences and patterns to offer hyper-personalized experience for consumers like us. But hyper-personalized experiences are challenging to achieve using traditional data management approaches prevalent in most organizations today. It requires a transformational approach, not just in tech, but most importantly in overall organizational approach and mindset on how to treat data assets. This new approach is what data products are all about.
In this paper we’ll briefly explore what data products really mean, their characteristics, and benefits. We’ll look at some examples of data products that our clients in financial services are building. In part 2 of this paper, we will discuss some key principles to consider while establishing a data product operating model.
Let’s begin with looking at current approach to data that is still prevalent in many organizations.
Today’s predominant approaches to data in organisations are inefficient, and incapable of meeting the future data volumes and data demands required to adopt AI at scale
Most financial services (FS) organisations are organised by different lines of business (LOB), each typically with its own set of customer onboarding systems (engagement) as well as core / transaction systems. With time and scale, the ecosystem gets quite complex resulting in duplication of information as well as inefficiencies in a variety of operational aspects such as reporting, servicing, analytics, etc. FS organisations have tried to address some of these issues over the years leveraging Master Data Management (MDM) systems, data warehouses, data lakes and so on; however, these fail to keep up with the scale and ever evolving business needs.
When divisions need data to build use cases around marketing analytics, financial reporting etc., they reach out to IT teams. IT teams often duplicate efforts to source (ingest from different source systems), clean and prepare data sets. The same process is repeated by IT teams for other use cases even though the data requirements often overlap between divisions. This creates the following challenges for IT and business.
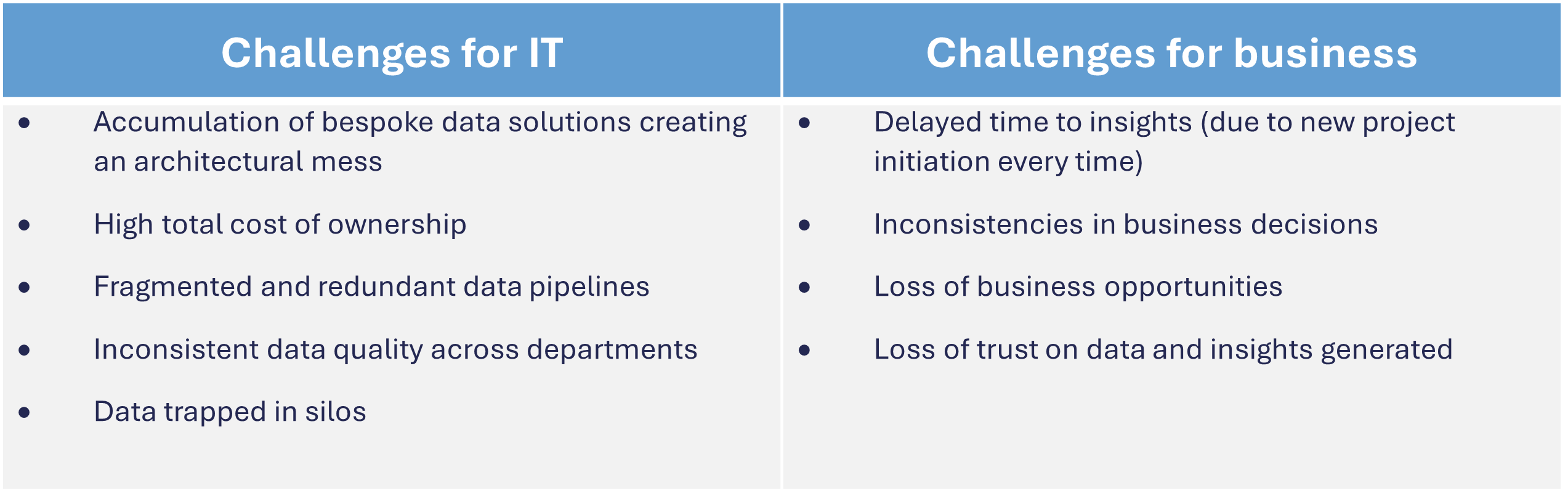
The traditional approach of bespoke solutions and manual interventions has just about worked for organisations so far. But today, data is being produced and shared across organisations at an unprecedented rate due to staggering number of digital services and offerings. With demands for more data and insights to sustain as well as drive business outcomes / growth, traditional / reactive approach is becoming untenable, and organisations need to shift their approach to adopt a data driven culture.
As per a Forbes report, data-driven companies that aim to making data a key differentiator are 23x more likely to acquire customers, 19x more likely to be profitable.
With the advent of Generative AI, establishing strong data foundations to fuel the AI era has become more critical. It’s a no brainer that organisations with higher data readiness will be much better placed to fully exploit the potential of generative AI, and data products could be the key to that.
So, what exactly are data products?
Data products are high quality, consumption-ready and reusable data assets that teams in an organisation can easily access to solve business problems. They are logically grouped data sets prepared through meticulous curation and cleansing of raw data from source systems and are underpinned by trust, integrity and reusability. (How they are logically grouped is covered in the article later).
Data products sit on top of existing warehouses or lakes, and once created they can be used by consumers/divisions within the organisation for various consumption needs such as, digital apps, AI/ML models, BI/Analytics dashboards, Reporting or third-party data sharing via APIs.
Data products require organisations to apply product mindset to their datasets. That means, lines of businesses (LOBs) treat their data assets as products, and consumers of that product across the organization as customers. Each data product has an owner who is accountable for its quality and reliability. And that is what fosters trust amongst consumers of the data.
LOBs create and manage data products to meet business needs. This is a shift from today’s approach in most firms wherein centralized IT department fulfil data requests and take accountability for quality and integrity of data that LOBs are producing.
HBR research indicates that a product-centric data approach yields significant efficiency gains, cutting implementation times by up to 90% and reducing costs by 30%.
Like any software product, data product follows the best practices of product management lifecycle. Here’s a typical data product lifecycle.
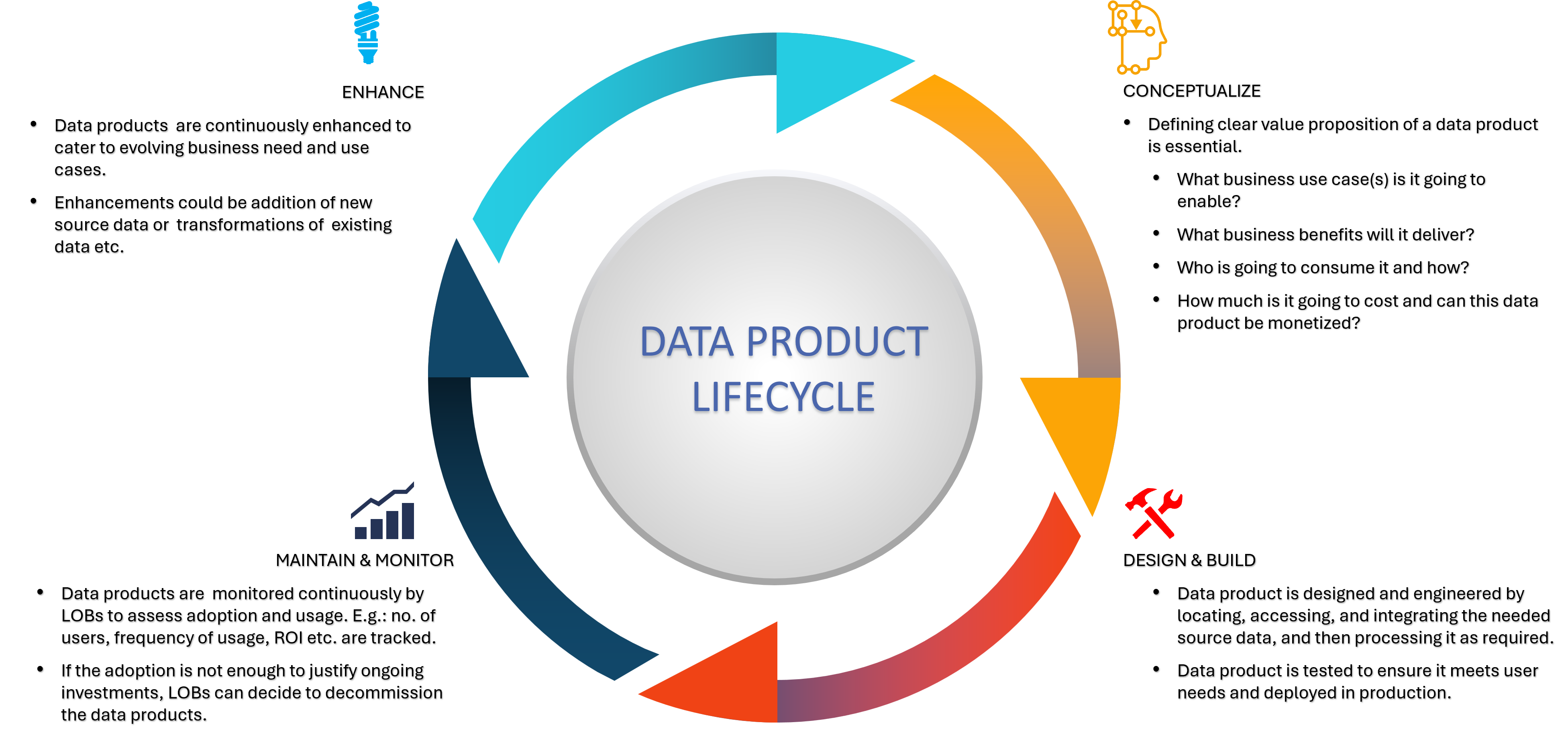
Let’s look at some benefits of data products

Financial services organizations are increasingly leveraging data products and to transition into AI-first enterprises
- JP morgan leverages data products which are shareable across enterprise to empower its internal stakeholders to make informed decisions.
- Regions bank has been employing data products for three and a half years. The initiative has proven highly successful, resulting in the launch of over 10 data products that directly generate revenue or reduce costs.
- HSBC Securities Services’ data strategy is focused on ‘data as a service’, which provides on-demand access to clients to their data products. Clients get financial market analytics, gain access to HSBC’s real-time and historic cross-asset data sets, and browse the latest market insights.
- UBS has been on a journey to implement data products to extract value out of their analytical data
- Nasdaq uses data products extensively to offers flexible access to high-quality historical data, ideal for research, strategy back testing, and compliance purposes. Their data products also provide consolidated real-time data from all Nasdaq Nordic and Baltic exchange systems, covering equities, derivatives, fixed income, commodities, and indexes
- A large APAC bank is on the journey of implementing data products with early focus around data products which will drive insights around uplift customer experience, personalization and risk management.
From our experience with financial services clients, we have seen firms categorize data products into two types:
Domain data products and cross-domain data products
1. Domain data products:
- These are essentially raw data set from bank’s core systems i.e. CRM, customer master, product ledgers etc that has been standardised, cleaned, transformed and organized as per domains.
- They are aligned with specific LOBs and provide domain specific insights but can be shared outside the LOBs with other units who need it.
- Ex – Mortgages data product would contain only mortgage data specific to mortgage LOB, such as detailed information on loan applications, origination details, servicing history, etc.
- It could help mortgages business users derive insights such as, what % mortgage customers with a home loan have an offset account? What % of home loan customers are rolling off from fixed to variable rate in next 6 months? etc.
- They provide foundations on top of which cross domain data products are built. (See category no. 2).
However, not all domain data products can be shared outside the LOB. Some domain data products are created to meet very niche requirements and can’t be shared outside of that domain/LOB due to variety of reasons (compliance, access restrictions etc.)
Example: Fin Crime data product that can be used to monitor transactions and prevent money laundering would typically serves very specific use cases for fin crime domain only. It may not be shared outside FinCrime domain as the use case is specific and there could be regulations that restrict data access.
2. Cross-domain data products:
- These are cross-functional and are designed for consumption across the enterprise not just a specific LOB.
- By integrating data from various source systems including domain data products (discussed above) and leveraging ML & AI, these enable use cases that provides holistic view of business, enabling organizations to identify hidden patterns, trends and revenue/cost saving opportunities.
- Their use cases and benefits cut across multiple LOBs and often requires several divisions/LOBs to agree, collaborate and co-develop.
- Ex – A Customer Insights data product could provide a holistic understanding of customer behaviour and preferences for multiple divisions in a firm. They could be used to identify high-value customers, enable hyper personalisation and identify cross-sell/upsell opportunities specific to their offerings and customers.
Data product examples in financial services firms
Below are some examples of data cross-domain and domain specific data products our clients have implemented in their organizations to unlock insights and drive business outcomes.

Conclusion
Looking ahead, the adoption of data products is likely to accelerate, driven by broad understanding and adoption of generative AI. Data products could provide the solid bedrock for financial services organisations to implement generative AI at scale in their enterprises. Firms that invest in building robust data product capabilities will be better positioned to navigate the gen AI era, meet evolving customer expectations and stay ahead in an increasingly data-centric world.










