In the previous blog, we saw the need for DataOps and understood at a high level what is DataOps. In this blog, we will dive deeper into the DataOps technology practices to be adopted
DataOps Practices
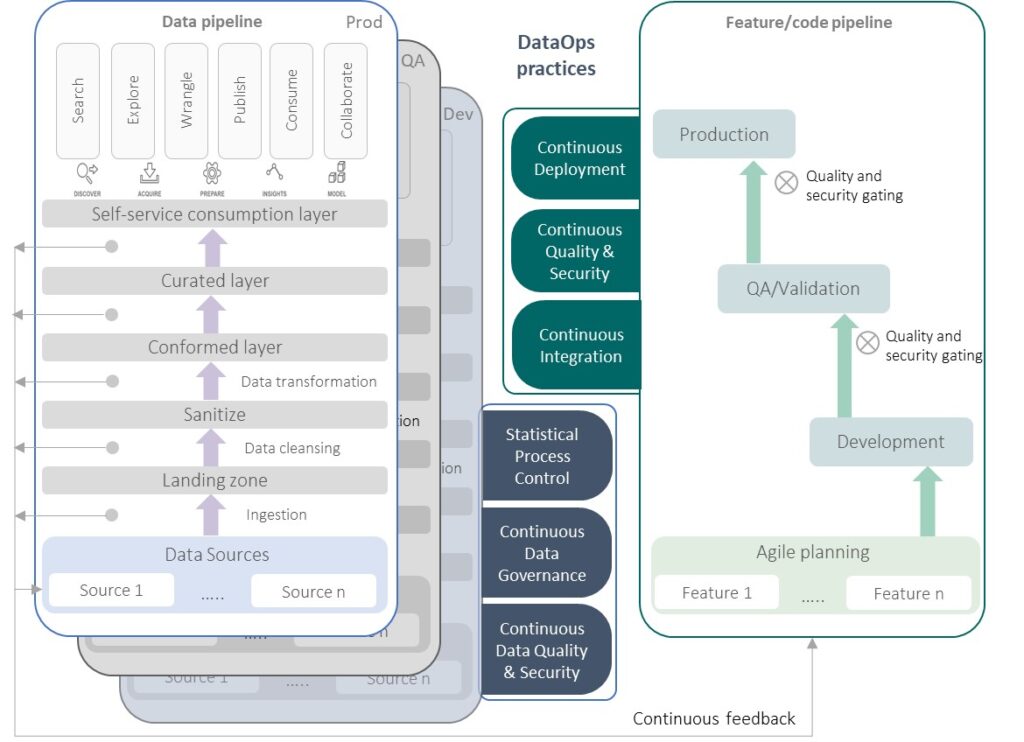
The DataOps technology practices encompass the code pipeline as well as the data pipeline.
Continuous Code Integration
Data schema, transformations, and report components should be treated as code. Ensuring that not only data transformation components but even data schemas and distribution/reporting components are maintained in a version control tool. Having essential practices automated into a Continuous Integration pipeline. Unit testing frameworks like TDD can be adopted to improve automation. Automated unit tests and build automation will help in the early detection of issues and improve repeatability. Frequent build automation helps identify issues quickly, especially when multiple team members work together. Changes in data programs sometimes require coordinated code and schema promotion across environments. The use of feature toggles reduces this dependency and allows for a faster and safer iterative code deployment process.
Continuous Code Testing and Security
Continuous testing and security results in improved quality of work products and reduces vulnerabilities. Good quality test data that represents real-world scenarios helps in comprehensive validation. Test data provisioning at speed can be achieved using test data management tools. We can shift left quality assurance using test automation for all code components to detect issues early. These can be run on each build, removing the need for extended testing cycles. Data and analytics applications are exposed to cyber threats and unauthorized access. Automated security scans for code covering SAST, SCA, and DAST/IAST should be implemented to avoid vulnerabilities.
Continuous Code Deployment and Environment Management
DataOps platforms allow for automated code promotion and release automation. This also includes automated roll-back of code components on failed deployment to return the system to a consistent state. The data platform consists of multiple systems, some of which are custom-built software while some are COTS and packages. Manual provision of environments with appropriate configuration takes time and impacts repeatability. The automation of environment provisioning with the required data storage, integration, and reporting components along with configuration for access control, roles, etc. reduces dependency and enables the team to focus on delivering valuable features. Infrastructure as code provides quick environment standup, autoscaling for high availability, and access/roles setup. Environment monitoring dashboards and automated alerts help in keeping a check and maintaining a stable system.
Continuous Data Governance
When data governance rules are codified and automated it provides more control in the data pipeline. DataOps tools can also provide automated data lineage and catalog generation. This makes data discoverable across platforms allowing rapid exploration. Orchestration is essential to automate the data processing from multiple sources and guide data through the various transformation stages. The orchestration engine should cater to high-velocity streaming data and high-volume batch information.
Continuous Data Quality and Security
The value of information increases with continuous data quality monitoring, automated gating, and alerting for completeness, accuracy, consistency, validity, and integrity. Similarly, automation of data contract monitoring gives confidence to business users in the information provided. To adhere to compliance guidelines, it is essential to incorporate automated data security for data at rest, data in motion, and access control.
Statistical Process Control and Audit
Data pipeline observability and a single view of data processing show how data flows across the system. Continuous monitoring of the data pipeline for performance, ensuring it’s within permissible service levels, and automated alerts help treat the data pipeline like a manufacturing line. This ensures consistent and predictable outcomes. Graceful data abends with auto recovery and protects the system from any upstream issues. Some systems also require data versioning and audit trails for recreating scenarios and provenance.
Here we can see how DataOps practices are applied as code moves across environments (Dev to Test to Production) and data moves from source systems to where it is consumed.
In the next blog, we will look at implementation strategies and the benefits of DataOps










My concern about AR / VR application ,I was wondering, if virtually people invite other privacy and keep
harassing what should victim person should do ?