As cybersecurity evolves into one of the most dynamic and complex fields, AI technologies like language models are essential for improving the speed and accuracy of threat detection, incident response, and risk mitigation. One of the most promising models for fine-tuning in the cybersecurity domain is LLaMA (Large Language Model Meta AI). In this blog, we’ll explore why fine-tuning LLaMA specifically for cybersecurity is crucial, and how you can leverage its capabilities to enhance cybersecurity chatbots and agentic AI systems.

Why a Local Model?
A key reason to fine-tune LLaMA for cybersecurity is the control and security benefits that come with deploying a local, on-premises model.
- Data Privacy & Security: By hosting LLaMA locally, you can avoid exposing sensitive cybersecurity data—such as threat intelligence, internal logs, or incident response records—to third-party cloud services. This reduces the risk of data breaches and leaks.
- Regulatory Compliance: Keeping the model on-premises helps ensure your organization stays compliant with regulations like GDPR, HIPAA, and other industry-specific standards, which often mandate that data remain within specific boundaries.
- Latency & Reliability: Real-time cybersecurity applications demand fast, low-latency responses. A local model can quickly analyze threats and provide recommendations, without depending on cloud infrastructure, ensuring consistent performance during critical situations.
- Custom Control: Hosting LLaMA locally gives you full control over updates, security patches, and access controls, providing flexibility and enhanced security.
Why Fine-Tuning?
Fine-tuning is the process of adapting a general-purpose language model like LLaMA to excel at specific tasks. In cybersecurity, fine-tuning involves training the model on specialized data to help it become an expert in areas like malware analysis, threat intelligence, and vulnerability management.
- Domain Specialization: Fine-tuning LLaMA on cybersecurity-specific data (e.g., CVE details, attack patterns, and malware behavior) transforms it from a general-purpose model into a cybersecurity expert. This improves its accuracy in understanding niche topics and terminology.
- Cost Efficiency: Fine-tuning allows you to leverage pre-existing knowledge, avoiding the need to train an AI model from scratch. With LLaMA’s linguistic skills, you can enhance its capabilities with minimal computational resources.
- Adaptability: Fine-tuning enables you to adjust LLaMA’s output to match your organization’s specific jargon, workflows, and tools (e.g., SIEM integrations), ensuring the AI is fully aligned with your operational needs.
Why LLaMA?
LLaMA, developed by Meta, offers several advantages that make it an ideal candidate for cybersecurity applications.
- Open Source: LLaMA is open-source, so you avoid vendor lock-ins. This transparency gives you complete control over audits, customization, and model updates, ensuring the AI meets security and compliance standards.
- Scalability: LLaMA is available in various model sizes, from 1B to 80B parameters. This allows you to choose a model that fits your resource constraints without sacrificing performance.
- Performance: LLaMA has demonstrated its efficiency in handling reasoning tasks, making it ideal for parsing technical cybersecurity information, like attack patterns or cyber threat intelligence (CTI).
Comparison of LLaMA with Other Open-Source Models
| Criteria | Llama 3.1 | GPT-4 | PaLM 3.0 |
| Model Architecture | Standard decoder-only transformer architecture. | Mixture-of-experts model (complex). | Architecture details not publicly disclosed. |
| Training Data | Trained on over 15 trillion tokens, data is publicly available. | Training data not publicly disclosed. | Specific data not publicly disclosed. |
| Use Cases | Suitable for cybersecurity tasks like threat detection, incident response, and security automation. | Versatile but less adaptable for cybersecurity due to its closed-source nature. | Use cases unclear due to lack of info. |
| Performance | Strong in general knowledge, math, tool use, and multilingual translation. Efficient and fast processing. | Excels in generating coherent and contextually relevant responses. | Performance metrics are not publicly available. |
| Accessibility | Open-source and freely accessible for customization. | Access via OpenAI’s API with potential usage costs and limitations. | Access details are not publicly available. |
| Scalability | Flexible deployment in on-premises, cloud, or hybrid environments. | Scalability is dependent on OpenAI’s infrastructure. | Scalability details are not publicly available. |
| Model Size Efficiency | Various model sizes with the flagship 405B parameter model. | Model size and parameters not publicly disclosed. | Model size and efficiency not disclosed. |
| Open-Source & Support | Community-driven support, open-source contributions. | Limited community contributions due to closed-source nature. | Support details not disclosed. |
Key Takeaways: How LLaMA 3.1 Stands Out
Open-Source Accessibility: LLaMA 3.1 offers full open-source access, making it highly customizable for local projects, including cybersecurity applications.
Transparent Training Data: With its publicly available training data, LLaMA 3.1 provides a high level of transparency that competitors like GPT-4 and PaLM 3.0 lack.
Scalability & Efficiency: LLaMA 3.1’s flexible deployment options and model efficiency ensure smooth integration into a variety of infrastructures while maintaining performance.
Community Support: LLaMA 3.1 benefits from active community contributions and support, making it a more dynamic and cost-effective choice for long-term projects.
Customization for Cybersecurity: Its suitability for cybersecurity tasks, paired with strong performance, makes LLaMA 3.1 the ideal model for developers looking for an open-source and powerful solution.
Model Offerings: 1B to 80B
LLaMA models come in various sizes, each suited for different cybersecurity needs:
- 1B-7B Models: Best for lightweight applications like chatbots or basic threat detection. These smaller models are faster, require less power, and are ideal for edge devices or smaller-scale applications.
- 8B-13B Models: Ideal for enterprise-level chatbots and real-time cybersecurity tasks. These mid-range models offer strong reasoning capabilities while maintaining efficiency.
- 30B-80B Models: Best suited for research or high-stakes cybersecurity analysis, such as predicting novel attack vectors. These larger models excel at complex reasoning but require significant computational resources.
The model size you choose impacts its ability to handle complexity, computational power needs, and the types of cybersecurity problems it’s suited to solve.
Model Types
LLaMA models come in different versions optimized for specific tasks:
- Base LLaMA: A general-purpose model used for a wide range of language tasks. It serves as a foundation for fine-tuning for specialized tasks.
- Instruct LLaMA: Fine-tuned to follow specific user instructions, making it ideal for conversational tasks like chatbots or personal assistants.
- Code LLaMA: Trained to understand and generate programming code. Ideal for use in software development, debugging, and code completion tasks.
- Chat LLaMA: Optimized for conversation-style tasks, offering natural, coherent responses, making it great for customer support bots or virtual assistants.
- Vision LLaMA: While still hypothetical, future versions of LLaMA may combine language and visual and tasks, such as visual question answering or image captioning.
- Multilingual LLaMA: A version trained in multiple languages, useful for global applications like multilingual translation and cross-language retrieval.
Each type of LLaMA model serves a unique need, offering versatility across various industries and use cases.
Training with the Right Dataset
The performance of a fine-tuned LLaMA model is highly dependent on the quality and relevance of the training data. In the cybersecurity domain, the right dataset can ensure that the model can effectively understand and respond to security threats, vulnerabilities, and incidents. Below, we’ll explore the types of datasets and inclusions that can optimize the model for cybersecurity tasks.
Unstructured Data
Training LLaMA on unstructured data sources—such as Cyber Threat Intelligence (CTI) reports malware analysis blogs, Stack Overflow threads, and incident response playbooks—enables the model to understand real-world cybersecurity scenarios. Additionally, anonymized logs from firewalls, IDS (Intrusion Detection Systems), and other security tools provide valuable insights into attack signatures and patterns.
Training on Stack Overflow & Blogs:
Q&A Format: Threads such as “How do you detect phishing emails?” can be used to train the model in problem-solving and troubleshooting in real cybersecurity contexts.
Jargon Familiarization: Exposing the model to cybersecurity-specific terminology like “zero-day,” “sandboxing,” and “EDR” ensures it understands the technical language of the industry.
Credibility Weighting: To ensure accurate and reliable information, higher priority should be assigned to answers from verified experts or trusted sources (e.g., content from the SANS Institute). This helps maintain the integrity of the knowledge LLaMA learns from.
Synthetic Data
Simulated attack scenarios and adversarial Q&A pairs help the model learn to respond to both known and emerging threats effectively. Leveraging sources like Attack CTI, CVE databases, and adversarial attack patterns can create diverse, synthetic training examples that simulate real-world attack scenarios.
Training with Attack CTI and Defend CTI, CAPEC, CVE, CWE:
To generate synthetic data, the model can utilize structured data from various threat intelligence platforms. Here’s how each source contributes to creating relevant training data:
AttackCTI:
This platform provides data on cyber threats, including tactics, techniques, and procedures (TTPs) used by adversaries. Data from AttackCTI can be mapped to common cybersecurity scenarios. For instance, descriptions of specific attack techniques can be paired with simulated questions to teach LLaMA how to identify and respond to various adversarial tactics.
Sample questions based on AttackCTI data:
- Technique Identification Questions: “What is technique T1071?” or “Can you explain the purpose of T1203?”
- Contextual Questions: “What is the primary objective of technique T1086?” or “How does T1071 affect my network?”
- Mitigation Strategy Questions: “What are the best countermeasures for T1071?” or “How do I prevent T1203 from being exploited?”
D3FEND Mappings:
The D3FEND framework outlines defensive techniques to counter specific attacks. By pairing these defensive actions with corresponding attack techniques, we create a rich dataset that teaches LLaMA how to suggest appropriate mitigations during cybersecurity conversations.
Example questions:
- Technique-focused Questions: “What defense measures are recommended against T1071?” or “How can I counteract the T1086 technique?”
- Defensive Action Queries: “What is the purpose of network segmentation defense?” or “How does file integrity monitoring help prevent attacks?”
- Implementation Questions: “How can I apply D3FEND’s recommendation for T1190?” or “Which defenses should be employed against phishing?”
CAPEC Data :
CAPEC (Common Attack Pattern Enumeration and Classification) contains a catalog of known attack patterns. Using the CSV file from the site, synthetic attack scenarios can be generated by combining different attack patterns with contextual information from other sources like AttackCTI. These synthetic attack scenarios will aid in developing a model that can understand various attack strategies and their technical nuances. This will improve Llama’s ability to generate informed cybersecurity responses when dealing with threats. Using the CAPEC data, we can create a variety of questions focusing on different aspects of attack patterns. These questions can address the nature, impact, and mitigation of specific attack patterns, allowing the model to generate more useful insights for users.
Attack Pattern Identification Questions:
· “What is CAPEC-100?”
· “Can you describe the attack pattern CAPEC-150?”
· “How does CAPEC-200 exploit vulnerabilities in web applications?”
Explaining the Details of Attack Patterns:
· “What techniques are used in CAPEC-134?”
· “Can you explain how CAPEC-145 works in a phishing attack?”
· “What is the objective of CAPEC-106 in a denial-of-service attack?”
Impact and Consequence-related Questions:
· “What is the impact of CAPEC-180 on database security?”
· “How does CAPEC-110 affect the confidentiality of sensitive information?”
· “What damage can CAPEC-118 cause to network infrastructure?”
Countermeasure and Mitigation Questions:
· “What defenses can prevent CAPEC-135?”
· “How do you protect against attacks like CAPEC-125?”
· “What mitigation strategies should be applied to prevent CAPEC-140?”
Comparative and Contextual Questions:
· “How does CAPEC-150 differ from CAPEC-140 in terms of attack strategy?”
· “Is CAPEC-160 more dangerous than CAPEC-170?”
· “Can CAPEC-105 be used in conjunction with CAPEC-120 in a complex attack?”
CVE Data:
The CVE database provides identifiers for publicly known cybersecurity vulnerabilities. Extracting data from the CVE API can be used to generate synthetic examples of specific vulnerabilities, including their severity, affected systems, and patching recommendations. By combining CVE information with corresponding attack patterns from CAPEC and defense strategies from D3FEND, a robust synthetic dataset can be created for Llama to learn vulnerability management, risk assessment, and mitigation techniques. Using the CVE data, we can generate questions in various forms that ask about specific vulnerabilities. For example:
- Informational Questions: “What is the CVE-2021-34527 vulnerability?” or “Can you describe the CVE-2020-1472 vulnerability?”
- Severity-related Questions: “How critical is CVE-2022-12345?” or “What is the impact of CVE-2021-1234?”
- Actionable Questions: “What is the fix for CVE-2021-3156?” or “Has CVE-2020-0601 been patched?”
CWE Data :
CWE (Common Weakness Enumeration) dataset, we can create a variety of questions that simulate different queries about software vulnerabilities and weaknesses. These questions will allow Llama to become proficient in understanding and responding to issues related to software security, helping it to provide more insightful guidance for developers, security researchers, and IT professionals.
For CWE Weakness Identification: We can create questions that ask about specific weaknesses identified in the CWE database. These questions may focus on the nature, impact, and technical details of a given weakness.
- “What is CWE-89?”
- “Can you explain the impact of CWE-20?”
- “How does CWE number 119 affect buffer overflow vulnerabilities?”
- “What does CWE-78 refer to in command injection attacks?”
For Vulnerability Details: These questions can provide detailed descriptions and explanations of a specific weakness, including examples of how the vulnerability can manifest.
- “What are the consequences of CWE 20?”
- “How does CWE-119: Improper Restriction of Operations within the Bounds of a Memory Buffer lead to security breaches?”
- “What systems are most susceptible to CWE-787: Out-of-Bounds Write vulnerabilities?”
For Severity and Risk Assessment: These questions help assess the severity of different weaknesses and vulnerabilities, which is crucial for prioritizing remediation efforts.
- “How severe is CWE-352: CSRF?”
- “Is CWE-190: Integer Overflow more dangerous than CWE-119?”
- “What kind of risks are associated with Improper Neutralization of Special Elements used in a Command?”
For Mitigation and Prevention: Questions related to mitigation and best practices help users understand how to prevent weaknesses from being exploited in software systems.
- “What are the mitigation strategies for CWE-89: SQL Injection?”
- “How can developers prevent CWE-287: Improper Authentication?”
- “What are the recommended defense techniques for preventing buffer overflow vulnerabilities like CWE-119?”
For Comparative and Contextual Questions: These questions compare and contrast weaknesses to help distinguish between similar vulnerabilities and understand their unique characteristics.
- “How is CWE-119 different from CWE number 120?”
- “What makes CWE-20 worse than CWE-83 in terms of security risk?”
- “Can CWE-89 and CWE-89.1 (SQL Injection variants) be mitigated using the same strategy?”
For Scenario-based Questions: We can also create synthetic scenarios where a particular weakness needs to be identified or mitigated.
- “If a web application is vulnerable to improper input validation, how would you fix it?”
- “A server has been compromised due to a buffer overflow. How do you mitigate this vulnerability?”
Training for RAG (Retrieval-Augmented Generation)
RAG allows LLaMA to retrieve external information and generate responses that are not only contextually accurate but also timely and relevant. By training the model on real-world cybersecurity events, we can enable it to retrieve relevant data from external sources and produce up-to-date answers for ongoing threats.
For example, if there is a major cybersecurity event like the Log4Shell vulnerability, LLaMA could be trained to pull from CVE databases, MITRE ATT&CK, and security advisories to generate accurate, real-time responses.
Example: Cybersecurity Event Context
Context: Suppose there’s a recent breach involving Log4Shell (CVE-2021-44228), a critical vulnerability in Apache Log4j that allows remote code execution.
Sample Questions:
- Vulnerability Identification: “What is CVE-2021-44228, and how does it exploit Log4j?”
Impact Assessment: “How severe is CVE-2021-44228, and what kind of damage can it cause to enterprise systems?” - Defensive Measures: “How can organizations protect themselves from Log4Shell (CVE-2021-44228)?”
Exploitation Scenarios: “What methods can attackers use to exploit CVE-2021-44228 in an unpatched system?” - Mitigation and Detection: “Which defensive techniques are most effective against attacks exploiting CVE-2021-44228?”
By feeding LLaMA with a mix of real-time cybersecurity events, it can become adept at handling emerging threats and providing timely responses to both known and new incidents.
Training for Agentic AI
To effectively train LLaMA to understand class and function comments, it is essential to create a diverse and extensive dataset. You will need at least 1,000 unique records to ensure the model captures a broad range of use cases and can generalize well. These records should cover a variety of different types of functions and classes, each with distinct comments describing their functionality, inputs, and outputs.
- For instance, class comments should describe various objects, from simple data structures to complex business logic. Examples might include:
Class Example:
# This class manages a library system, handling the addition, removal, and searching of books.class LibrarySystem:
# class definition
- In addition to this, the dataset should also include classes related to user interfaces, database models, and network protocols, ensuring that LLaMA is exposed to a wide range of contexts. For example, you might include:
Class Example:
# This class handles database connections and queries, ensuring secure and efficient data retrieval.class DatabaseConnection:
# class definition
Similarly, for function comments, it is important to provide examples that span different data types, operations, and expected outputs. Each function comment should clearly describe the input parameters and the expected output format. Training data should include at least 1,000 examples across various types of functions, such as mathematical operations, data transformations, and string manipulations. For example:
- Function Example
# This function checks whether a number is prime.
# Input: An integer.
# Output: True if the number is prime, False otherwise.
def is_prime(number: int) -> bool:
# function definition
Moreover, you’ll want to include variations such as functions that process lists, dictionaries, and other data structures, ensuring LLaMA understands how different inputs affect outputs. For example:
- Function Example
# This function calculates the total cost of items in a shopping cart.
# Input: A list of item prices (floats).
# Output: The total cost as a float.
def calculate_total(cart: list) -> float:
# function definition
By creating a dataset with a diverse set of records—comprising various types of functions, classes, and comments for different scenarios—you will ensure that LLaMA is effectively trained to understand and apply class and function comments in a wide variety of programming contexts. This extensive dataset will enable the model to generalize well and accurately interpret different types of code, improving its performance in understanding when and how to use classes and pass inputs/outputs to functions.
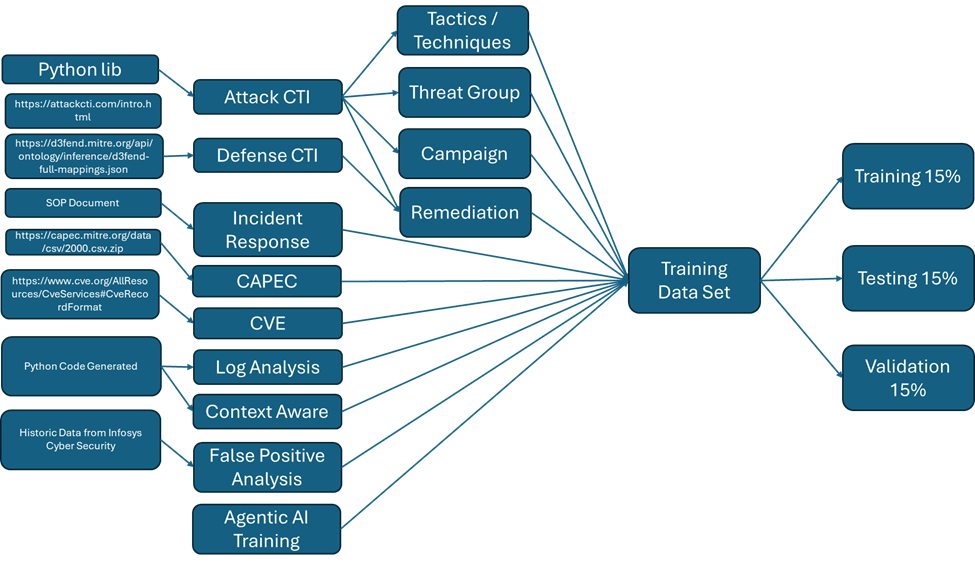
Diagram Representation of Various Data Sources for Training the Model
Which Environment Is Best for Fine-Tuning Your LLaMA Model?
Cloud GPU Solution
Amazon Web Services (AWS)
- Key Features: AWS provides robust cloud computing services, including EC2 instances with GPUs (e.g., p3, p4, and g4dn instances) for training large models. Amazon SageMaker is a fully managed service that supports building, training, and deploying machine learning models end-to-end.
- Best For: Large-scale model training, flexible pricing, and seamless integration with a wide variety of AWS services.
Google Cloud Platform (GCP)
- Key Features: GCP offers compute instances with GPUs (e.g., NVIDIA Tesla T4, P100, A100) and an AI Platform for model training. It also supports TensorFlow, PyTorch, and other popular deep-learning frameworks.
- Best For: Scalable machine learning pipelines, high-performance GPUs, and strong integration with Google’s AI services.
Microsoft Azure
- Key Features: Azure provides GPU-powered instances, such as the ND and NC series, tailored for deep learning tasks. Azure Machine Learning Studio offers a comprehensive suite of tools for model training, deployment, and management at scale.
- Best For: Seamless integration with enterprise solutions, robust machine learning tools, and hybrid cloud deployments.
IBM Cloud
- Key Features: IBM Cloud offers GPU-accelerated virtual servers and an AI platform for building, training, and deploying machine learning models. It also includes Watson Studio to streamline data science workflows.
- Best For: Companies seeking enterprise-level AI solutions and advanced analytics platforms.
Oracle Cloud Infrastructure (OCI)
- Key Features: Oracle provides specialized GPU instances optimized for high-performance computing and AI training, with support for TensorFlow and PyTorch. Managed machine learning and data science environments are also part of the offering.
- Best For: Enterprises that already use Oracle’s suite of cloud tools and require GPU instances designed for specific use cases.
In-House GPU Solutions
Using Unsloth Library for GPU Utilization
- Key Features: Unsloth is a library that streamlines GPU resource utilization for deep learning tasks. For in-house GPU setups, particularly smaller servers or workstations, Unsloth can help optimize multi-GPU usage or automate model fine-tuning workflows.
- Best For: Teams with dedicated hardware and the need for optimized, smaller-scale training environments.
Dedicated Workstations or Server Farms
- Key Features: Organizations can use high-performance GPUs like the NVIDIA A100, V100, or RTX 3090 for fine-tuning models in-house. While these setups require a significant initial investment, they provide complete control over hardware and security.
- Best For: Teams needing full control over hardware and data security, and organizations that can manage the upfront costs.
Free or Low-Cost Options for Fine-Tuning Models
Google Colab (Free Tier)
- Key Features: Google Colab offers free access to NVIDIA T4 GPUs, with a 6-hour session limit. For enhanced resources, Colab Pro (paid) provides access to more powerful GPUs, extended runtimes, and priority access.
- Best For: Small-scale fine-tuning tasks or prototyping, especially for students or individuals with budget constraints.
Kaggle Kernels
- Key Features: Kaggle provides free GPU access (typically NVIDIA T4 or P100) for running notebooks, often used in data science competitions. The free access is limited, but Kaggle offers a wide variety of community-driven datasets and pre-trained models.
- Best For: Quick experimentation or small-scale model training, particularly for data science practitioners.
Other Notable Options
Paperspace
- Key Features: Paperspace offers GPU-powered virtual machines (e.g., Tesla P100, V100, A100) designed for deep learning tasks. The platform also features Gradient, a toolset for building, training, and deploying models with integrated tools.
- Best For: Cost-effective cloud training, with a focus on simplicity and accessibility for developers.
Lambda Labs
- Key Features: Lambda Labs provides cloud GPU instances, pre-configured deep learning environments, and workstation setups optimized for AI workloads. Their services are tailored for high-performance training needs.
- Best For: Researchers or companies that need specialized hardware and deep learning environments for AI development.
FloydHub
- Key Features: FloydHub simplifies managing machine learning projects with its user-friendly platform for training, managing, and deploying models. It offers cloud GPU instances on demand.
- Best For: Teams or individuals who want a simple interface to manage machine learning projects and training pipelines.
Hybrid Solutions
On-Premise + Cloud Integration
- Key Features: Many organizations opt for hybrid cloud setups that combine on-premises infrastructure for sensitive data with cloud resources for scalable computing power. Tools like Kubernetes enable seamless orchestration between local and cloud environments.
- Best For: Organizations with strict data privacy concerns, but who also need the scalability of cloud resources for complex model training.
Additional Considerations
When fine-tuning LLaMA for agentic AI tasks, particularly in cybersecurity and programming contexts, it is crucial to implement ethical guidelines, adversarial robustness measures, and continuous learning strategies to ensure the model behaves responsibly, and securely, and stays current with evolving threats. Below is an overview of these key principles:
1. Ethical Guardrails
It is vital to ensure that LLaMA refuses harmful or dangerous queries, especially in cybersecurity, where malicious activities can be inadvertently promoted. The model should be trained to reject requests for guidance on harmful actions, such as “How to build ransomware?” or “How to exploit a zero-day vulnerability?” by providing ethical disclaimers instead. The following practices help establish these guardrails:
- Dataset Curation: Removing harmful content from training datasets to prevent the inclusion of malicious techniques or activities.
- Guardrail Prompts: Incorporating prompts during fine-tuning that specifically instruct the model on how to respond to illegal or harmful queries. For example, if asked to create malware, LLaMA should respond with, “Sorry, I cannot assist with that. Please refer to ethical cybersecurity guidelines.”
- Ethical Frameworks: Developing a framework that promotes positive, legal outcomes, such as educating users on defensive strategies rather than encouraging offensive actions.
2. Adversarial Robustness
Adversarial attacks, like prompt injections, aim to manipulate the model into disclosing sensitive information or performing harmful actions. It is essential to test the model’s resilience against such attacks in the cybersecurity context. Strengthening adversarial robustness can be achieved through the following approaches:
- Adversarial Testing: Introducing adversarial examples during training to evaluate how the model reacts to prompt injections. For instance, an attacker might alter a query to try and retrieve sensitive data like “What is the CVE for the latest ransomware?” The model must detect these attempts and refuse to disclose such information.
- Safety Layers: Adding layers of security to ensure sensitive data, such as personal information or classified cybersecurity intelligence, is flagged and protected from unauthorized exposure.
- Input Sanitization: Implementing checks to confirm that inputs are safe and do not contain hidden commands or manipulative instructions that could compromise security.
3. Continuous Learning
Cybersecurity is a constantly changing field, and for LLaMA to remain effective, it must stay updated on new threats, vulnerabilities, and defense strategies. Continuous learning ensures that LLaMA provides accurate and timely responses to real-world incidents. Here’s how continuous learning can be maintained:
- Regular Model Updates: Establishing a pipeline to frequently update the model with new information, such as CVEs, emerging attack vectors, and updated defense techniques, ensures that LLaMA remains current with the latest cybersecurity developments.
- Automated Data Ingestion: Creating systems that automatically process new cybersecurity reports, advisories, and threat intelligence. For example, once a new CVE is discovered, it should be immediately integrated into the training dataset.
- Real-time Threat Feeds: Connecting the model to live feeds of cybersecurity threats (e.g., from MITRE ATT&CK or threat intelligence platforms) helps LLaMA receive continuous updates on active or newly discovered threats, ensuring the model remains relevant and can respond to contemporary incidents.
By focusing on ethical guardrails, adversarial robustness, and continuous learning, LLaMA will be better equipped to provide valuable, secure, and responsible assistance in cybersecurity tasks, adapting to new challenges and evolving threats in this dynamic field.
Updating RAG Vector Database and Retraining for Continuous Improvement in Cybersecurity Q&A
As cybersecurity threats evolve rapidly, it’s crucial that the LLaMA 3.1 8B model remains responsive to emerging challenges and delivers accurate, relevant answers to users’ cybersecurity-related queries. To ensure the system stays current and effective, we’ve designed a robust pipeline for continuously updating the model’s knowledge base and fine-tuning its responses. Below, we outline our approach to ensure ongoing improvement and adaptability of the system in the face of ever-changing cybersecurity threats.
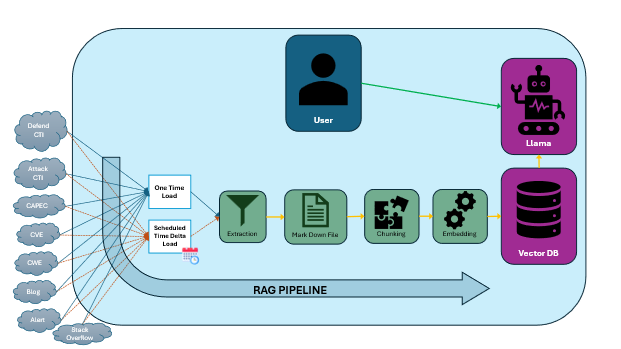
Tracking the “Delta” of Cybersecurity Changes
In the fast-paced world of cybersecurity, new threats, vulnerabilities, and countermeasures emerge frequently. To maintain the relevance and accuracy of the LLaMA model’s responses, we will implement a continuous monitoring pipeline that constantly tracks the latest trends and developments.
This pipeline will aggregate data from a variety of trusted sources, including news outlets, threat intelligence feeds, academic papers, and industry reports. By identifying the “delta” or the difference between newly acquired data and the current knowledge stored in the system, we can ensure that the model is updated with only the most relevant and critical information.
Every four hours, this new information will be processed and used to update the Vector Database, ensuring that the model remains in sync with the latest cybersecurity intelligence. The source of data is as shown in the diagram above. This rapid cycle of data updates enables the model to quickly adapt to evolving cybersecurity challenges and provide users with the most up-to-date and accurate answers.
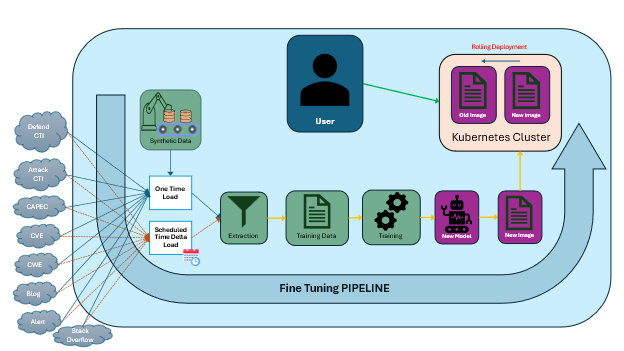
Weekly Retraining for Fine-Tuning
In addition to frequent updates to the Vector Database, we will incorporate weekly retraining sessions to fine-tune the LLaMA model. The new data collected over the week, combined with insights gleaned from user interactions, will provide a rich dataset for training the model.
This retraining process allows us to incorporate real-world feedback, ensuring that the model stays up-to-date with emerging threats and improves its accuracy and relevance based on how users engage with it. By analyzing patterns in user queries and identifying any knowledge gaps, we can refine the model’s responses and enhance its understanding of complex cybersecurity topics.
The weekly fine-tuning process will leverage both the latest threat data and the ongoing interaction between the model and its users, creating a feedback loop that drives continuous improvement. This iterative approach ensures that the model remains sharp, accurate, and highly adaptable to the dynamic landscape of cybersecurity.
Applications of Fine-Tuned LLaMA Model in Cybersecurity
Fine-tuning LLaMA for cybersecurity enables organizations to automate and enhance key aspects of cybersecurity defense, providing a range of powerful applications.
1. Threat Intelligence and Analysis (with Agentic AI)
Fine-tuned LLaMA models can be deployed to analyze live threat feeds in real time. By incorporating agentic AI capabilities, the model can autonomously process incoming threat intelligence (e.g., CVEs, indicators of compromise) from multiple sources (e.g., MISP, threat-hunting tools). This empowers LLaMA to correlate new attacks, recommend mitigations, and even trigger defensive actions, such as blocking IP addresses or isolating affected systems.
- Live Feed Parsing: The model can quickly parse live threat data, identify security incidents, and provide actionable recommendations.
- Autonomous Responses: With agentic AI, LLaMA can autonomously block malicious IPs, apply patches, or notify administrators of critical incidents.
2. Threat Hunting with a Fine-Tuned Model
Fine-tuning LLaMA for threat hunting automates the detection of suspicious activities, anomalies, and previously undetected attack vectors. The model can be trained on datasets like historical incident logs, attack patterns, and simulated attack data, helping analysts uncover threats more efficiently.
- Automated Analysis of Logs: The model can sift through large volumes of logs, identifying patterns indicative of security threats.
- Anomaly Detection: By leveraging machine learning techniques, the model can detect anomalies based on historical data and proactively flag potential threats.
3. Creating Playbooks for SOAR (Security Orchestration, Automation, and Response)
By fine-tuning LLaMA, organizations can automate the creation of security playbooks for tools like SOAR. LLaMA can be trained on various incident response scenarios, allowing it to generate detailed, context-specific playbooks, reducing manual effort and accelerating response times.
- Incident Detection: LLaMA can suggest the next steps for incidents like DDoS attacks, such as blocking IP ranges and applying rate-limiting.
- Custom Playbook Creation: The model can create playbooks tailored to specific incidents and seamlessly integrate them into SOAR.
4. Creating SOPs (Standard Operating Procedures) for SOC Analysts
Fine-tuning LLaMA for your organization’s security operations ensures it can generate tailored Standard Operating Procedures (SOPs) for your Security Operations Center (SOC). SOPs ensure that analysts follow consistent, effective response procedures during a security incident.
- Detailed Incident Response: LLaMA can generate step-by-step procedures for various security incidents, like malware infections or unauthorized access.
- Tool-Specific SOPs: The model can create SOPs specific to tools used in the SOC, such as Splunk or Wazuh, ensuring that workflows are tailored to each tool and log source.
5. Incident Remediation: How SOPs Enhance Efficiency
Once SOPs are in place, they can guide analysts through the incident remediation process, improving speed and accuracy. A fine-tuned model can ensure that no critical steps are missed during remediation.
- Automated Incident Resolution: By following predefined SOPs, LLaMA can guide analysts or autonomously perform corrective actions, significantly reducing the time to resolve incidents.
6. Automating ITSM Ticket Creation for Cybersecurity-as-a-Service
In a cybersecurity-as-a-service setup, fine-tuned LLaMA can automate ITSM ticket creation for client security incidents. By leveraging threat intelligence, incident logs, and alerts, the model can automatically generate ITSM tickets in platforms like ServiceNow, Jira, or Zendesk.
- Automatic Ticket Generation: Upon detecting a security incident (e.g., phishing or DDoS attack), LLaMA can generate a detailed ITSM ticket, complete with relevant details, such as severity and affected systems.
- Client-Specific Tickets: The model can tailor ticket generation to meet client-specific needs, incorporating their preferred templates, communication methods, and escalation paths.
Conclusion
Fine-tuning LLaMA for cybersecurity tasks, particularly in chatbots and agentic AI systems, offers organizations a transformative opportunity to enhance their defenses against evolving cyber threats. By customizing the model to understand the unique nuances of cybersecurity, you create a responsive, intelligent system capable of analyzing complex threats, making autonomous decisions, and providing real-time support.
Leveraging LLaMA’s open-source flexibility, scalability, and performance capabilities enables cybersecurity professionals to stay ahead of emerging challenges. With the right datasets, ethical considerations, and continuous updates, LLaMA becomes an invaluable asset in the cybersecurity toolkit.
References
https://cwe.mitre.org/
https://www.cve.org/AllResources/CveServices#CveRecordFormat
https://capec.mitre.org/data/csv/2000.csv.zip
https://d3fend.mitre.org/











