Introduction
The world of artificial intelligence is witnessing a transformative era, with the convergence of powerful tools like Large Language Models (LLMs) and advanced image analysis. This convergence is particularly exciting for video analysis, opening doors to new ways of extracting insights from visual media for critical business applications. This methodology bridges this gap by utilizing LLMs to intelligently select keyframes for deeper analysis.
Let’s deep dive into the process.
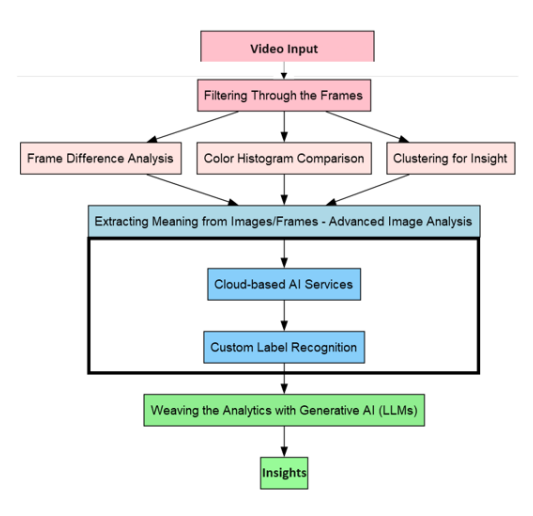
1: Filtering Through the Frames
A video is essentially a collection of images (frames), and the challenge lies in efficiently analyzing this data. Examining every frame is a brute-force approach that’s neither cost-effective nor scalable.
Here, intelligent frame sampling techniques come into play:
- Frame Difference Analysis: This technique calculates the difference between consecutive frames. Frames with significant changes are flagged as keyframes, indicating potentially important events.
- Color Histogram Comparison: By comparing the color distribution (histogram) of successive frames, significant changes can be detected, potentially signifying a scene shift or an important event.
- Clustering for Insight: We can treat video frames as high-dimensional data points. By applying clustering algorithms, similar frames are grouped together. The representative frame of each cluster is then analyzed as a keyframe.
We can use any of the above-mentioned techniques or a combination of all.
2: Extracting Meaning from Images/Frames – Advanced Image Analysis
Once keyframes are identified, we delve into advanced image analysis using cloud-based AI services (Amazon Rekognition, Microsoft Azure Cognitive Services Computer Vision, or Google Cloud Vision AI). These services go beyond traditional OCR, offering exceptional accuracy in extracting text and associated labels from images. Imagine analyzing a frame to identify an object or action. Additionally, these services can extract visible text and classify the image with labels like “car” or “door closing”, providing a dual understanding of content and context. Furthermore, custom label recognition empowers the system to identify specific elements, allowing you to define labels for objects like company logos, etc.
3: Weaving the Analytics with Generative AI (LLMs)
With text and labels extracted from sequential video frames, we can leverage the power of generative AI to interpret the story unfolding within the video. Why generative AI? This technology excels at handling unstructured data, that is, precisely what we have after Step 2. LLMs can read, understand, and narrate the story behind the sequence of frames and extracted data. In simpler terms, LLMs convert the features of individual frames or the entire sequence into a clear textual description.
An LLM offers two crucial insights:
· Understanding Individual Frames: What’s happening in each image/frame?
· Connecting the Dots: A clear and concise explanation of the flow or event depicted in the video.
Let’s break down frame filtering using a generic approach:
Imagine a security camera recording a hallway. We don’t need to analyze every frame to see if someone walked by. Here’s how frame filtering with Frame Difference Analysis could work:
· Analyze the difference between two consecutive frames (Frame 1 & Frame 2).
· If the difference is significant (a large area of pixels changed color), it suggests movement.
· If the difference is minimal (mostly the same colors), it likely means little to no movement.
This way, we only analyze frames with significant changes, focusing on potential events (someone walking by) and skipping redundant frames.
Now, let’s use sample frames and see how Image Analysis with LLM Integration might work:
Sample Video: A person (wearing a red jacket) walks into a kitchen, opens the fridge, and takes out a milk carton.
Frame 1: Shows a closed fridge door.
Image Analysis: LLM wouldn’t glean much as there’s minimal movement or change.
Frame 2: The person reaches for the fridge handle.
Image Analysis: Cloud-based AI services might detect a human hand and possibly the outline of the fridge.
Frame 3: The fridge door is open, revealing shelves with food items.
Image Analysis: Services could identify the open fridge, potentially recognizing shelves and various food containers.
Frame 4: The person holds a milk carton.
Image Analysis: Services might detect a human hand holding a rectangular object with a label (milk carton).
LLM Integration: Here’s where it gets interesting. The LLM, seeing the sequence of frames and image analysis data, could generate a description:
“A person wearing a red jacket walks into the kitchen and opens a refrigerator. He reaches in and takes out a milk carton.”
This combines the individual frame analysis into a cohesive understanding of the entire video clip. This is a simplified example. Real-world LLMs are more sophisticated and can handle complexities.
With the advancement of LLMs, it is now possible to directly process the image/frame without the need to extract the labels and text. So, imagine the capability it will possess if we merge the previously mentioned methods, along with the latest LLMs like GPT4 vision, GPT-4o, GPT-5, etc.
This output can be further analyzed by the LLM for a more nuanced understanding. While LLMs can refine the output for deeper insights, processing long videos remains a challenge due to input size limitations.
Here’s how we can tackle this challenge:
Segmentation: The video is divided into segments, each adhering to the LLM’s processing limit.
Overlap Integration: Information from adjacent segments is incorporated to maintain context.
Sequential Analysis with Summary: Summaries are generated for each segment, aiding the LLM in comprehending the overall narrative.
By combining advanced image analysis with the power of LLMs, we unlock a new era of video analysis, extracting valuable insights and transforming visual data into a compelling narrative.
Conclusion
The advancement of image analysis and LLMs marks a turning point in video analysis. This powerful combination unlocks a treasure trove of insights previously hidden within visual data. Imagine automatically generating summaries of surveillance footage, extracting key moments from educational videos, or gaining a deeper understanding of customer behavior in marketing materials and, as part of accessibility, it can be harnessed to automatically generate audio descriptions and captions for videos, make video content more accessible for visually impaired and deaf audiences. The possibilities are truly vast.
As LLM technology continues to evolve, with increased processing power and even more sophisticated capabilities, we can expect even richer narratives to be woven from video data. This future holds immense potential for businesses across various sectors, empowering them to gain a deeper understanding of their surroundings and make data-driven decisions that propel them forward.












reading the images frame by frame and extracting the meaningful features to consilidate them into new features while applying to the video to better analyse the video for the proper synthesis of information. This whill better help in video extension generation and video reconstruction from the blurred videos and recommendation system for physical AI