Test data is an important part of a company’s data strategy. It is a vital component for quality assurance and ensuring the delivery of a quality product. Is it difficult to set up the right test data? The answer depends on several factors, such as data landscape complexity, data requirements, test types, etc. Test data set-up can be one of the most tedious tasks in the software test life cycle and can take up approx. 60-70% of a quality assurance engineer’s effort. Despite this, we see that several organizations fail to recognize the need for Test Data Management (TDM) in their application development and test processes. Test data management falls into the Good-to-Have bucket rather than the Must-Have. Slowly but steadily, we are seeing a change in this trend. Enterprises are moving towards adopting test data management strategies to achieve seamless test automation and improve application quality. Furthermore, the need for proper data management strategies is highly crucial for the development of data-centric solutions.
So, what are the different techniques and practices that can be adopted to set up test data?
Most enterprise technology leaders are unaware of the right data management processes that need to be brought in for software testing. Adopting the right data strategy is extremely crucial for success, and it should be done basis the data landscape and test data needs of the organization. Some of the commonly used techniques are depicted below:
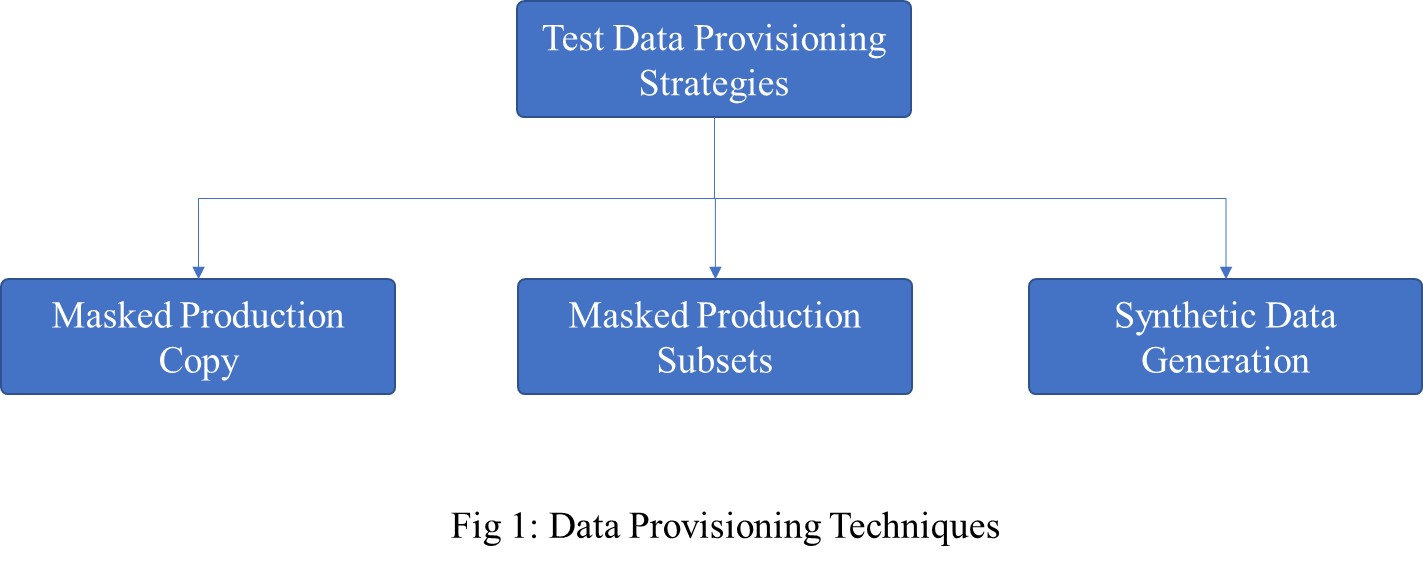
Traditional techniques for test data provisioning usually involve taking a copy of production data, masking it to ensure all sensitive data elements are desensitized and then provisioning this data to non-production environments. This is a decent strategy to get production-like test data. But does this suffice all your testing requirements? The answer is “No”. For instance, for scenarios where specific combinations of data are not present in production environments, data for negative test conditions, large volumes of data for performance/stress tests, etc., will always need a different approach to set up the desired test data. This is where a synthetic data generation strategy can help. With stricter data privacy regulations across the world, the usage of production data is highly under scrutiny, and multiple organizations are slowly moving towards synthetic data as a strategy for test data provisioning.
What is Synthetic/Fictive Data?
Synthetic or Fictive data generation is a technique for creating real-like fictive data using defined procedures and algorithms. This strategy gives the user better control to generate the right and precise test data sets based on their test conditions. Data can be generated programmatically using pre-built algorithms or by creating clones of existing data.
Few of the advantages of synthetic data are:
- Reusable: Data generation rules or techniques can be configured once and executed on demand to generate desired volumes of data.
- Customizable: Any data combination can be synthetically generated for testing needs.
- Privacy compliant: Synthetic data adhere to data privacy laws by default. Since synthetic data is fictive and does not relate to any real entity, adherence to data regulations is met with its usage.
- Scalable: It is possible to generate test data in any desired volume.
- Easier to gather: Synthetic data can be easily set in scenarios where real data can be dangerous to collect. For example, building an AI-based car crash prevention system would require data on actual car crashes, which may be challenging to gather. This can be synthetically generated instead.
Now, let us look at the various techniques for synthetic generate data.
There are 2 methods for generating synthetic data:
1. Rule-Based
2. Machine Learning (ML)-Based
Rule-Based Data Generation
This process of synthetic data generation begins with gaining a clear understanding of what needs to be generated. Rule-based data generation uses prebuilt data generation rules or algorithms for synthetically generating the data. A model needs to be created with data generation rules defined for all the required entities. Once this is done, data can be generated on demand. Products like Infosys Enterprise Data Privacy Suite (iEDPS), Broadcom TDM, and GenRocket help in rule-based data generation.
Rule-based data generation can be further classified into Purely Fictive and Partially Fictive. In purely fictive data generation, algorithms must be defined for all the entities of the dataset. As shown in the below figure, data generation algorithms are defined for each entity within the data objects, products and orders.

Fig 2: Purely Fictive Data Generation
In partially fictive data generation, rules are defined for only required entities. Remaining entities that are not sensitive in nature can take some default, preset values, or copy values from actual data. Below is a depiction of partially fictive data generation:
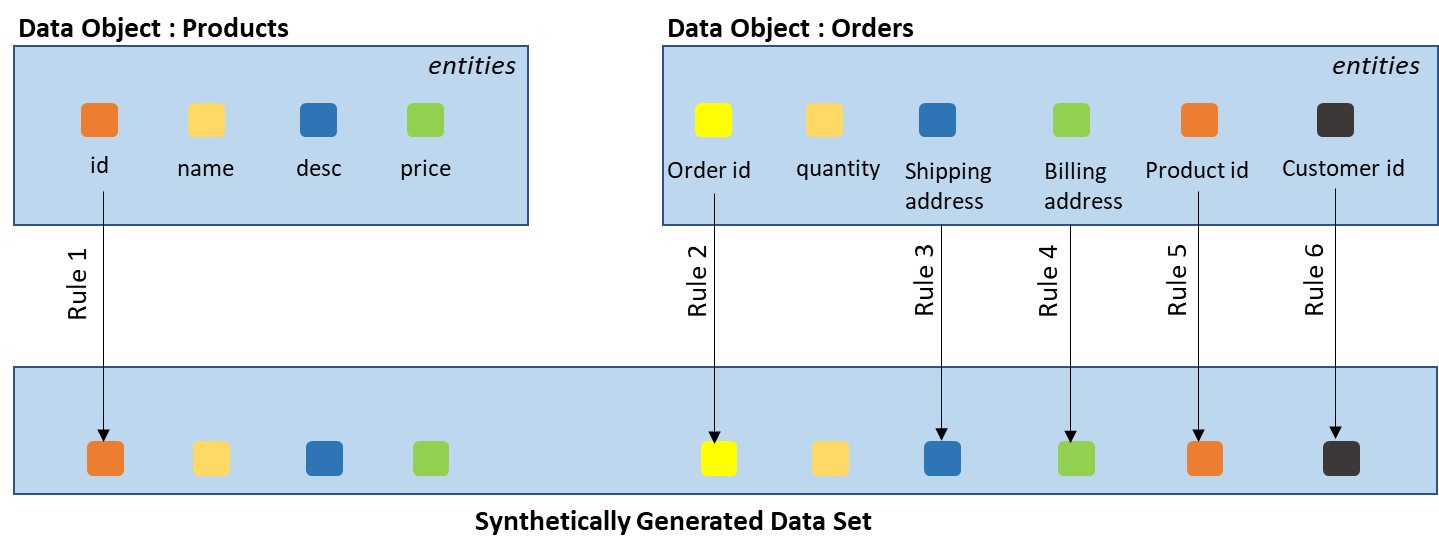
Fig 3: Partially Fictive Data Generation
Machine Learning (ML)-Based Data Generation
ML-based data generation is a technique in which an unsupervised learning task discovers and learns insights and patterns in data in such a way that the model can be used to output new data samples that match the same distribution as the real-world data it was trained on. Generative modelling is one of the most advanced techniques used to create synthetic data, and this often starts with data collection and then training the model to generate additional data. There are several products, such as Gretel.ai, Hazy, Infosys Enterprise Data Privacy Suite (iEDPS), Mostly.ai, etc., which support ML-based data generation.
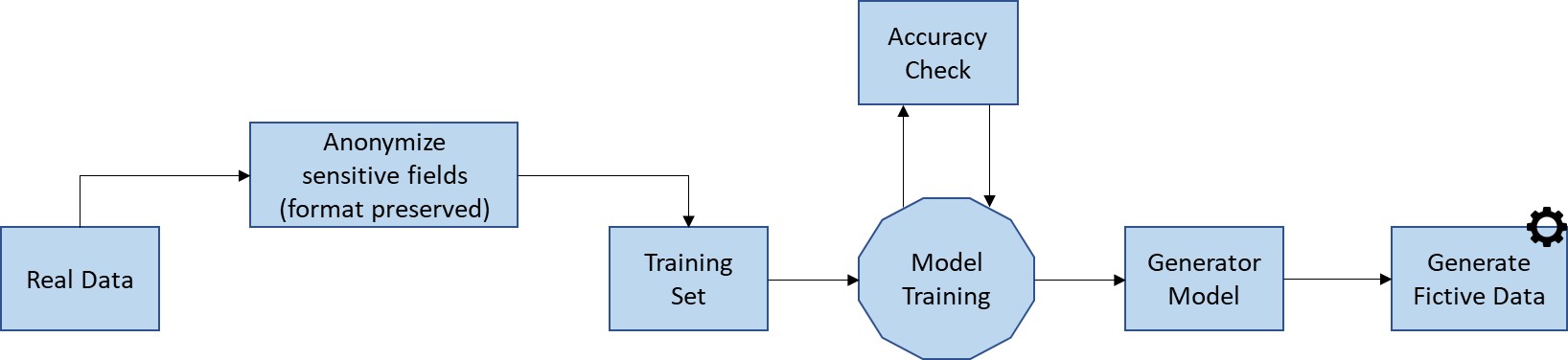
Fig 4: Model Based Data Generation
Conclusion
The need for high-quality training data sets, high quantity of data, challenges involved in the collection of real data, stricter privacy regulations governing data usage, and being fully user controlled are a few of the many reasons why organizations are choosing to move towards synthetic data generation. Along with these advantages, there are a few challenges associated with synthetic data, such as the whole data generation process requires expertise, time and effort.
A hybrid approach comprising leveraging masked production extracts along with synthetically generated data would be the best bet for enterprise-wide TDM implementations. This approach ensures the availability of all combinations of test data in desired quantities for software testing needs.








