When you place too much attention on the boundaries, you fail to see the big picture. That mindset has long shaped data management in the upstream sector, and it is precisely what now limits performance.
Organizations have invested heavily in data systems across exploration, drilling, completions, production, facilities, and engineering. Yet the industry continues to face incidents rooted not in lack of data, but in fragmented information and weak cross‑functional visibility. The results can be severe: poor casing design driven by unanalyzed pore pressure data, misleading production forecasts due to inaccurate mapping of well master data, or even pipeline ruptures in Ecuador linked to inadequate geological hazard mapping. The major disasters, from Piper Alpha (1988) to Deepwater Horizon (2010), differ in context, but share a common thread: critical insights were present, but not connected; Information asymmetry leading to lost opportunities for intervention.
Upstream data is not a by-product; it is the operational backbone. The challenge is not collecting more data but managing it as an end-to-end chain, one that transforms heterogeneous datasets into reliable, decision‑ready intelligence across the lifecycle of an asset.
Leaders must reflect on the patterns repeatedly observed across upstream digital initiatives and what it truly takes to build a connected data management function and environment ready for AI.
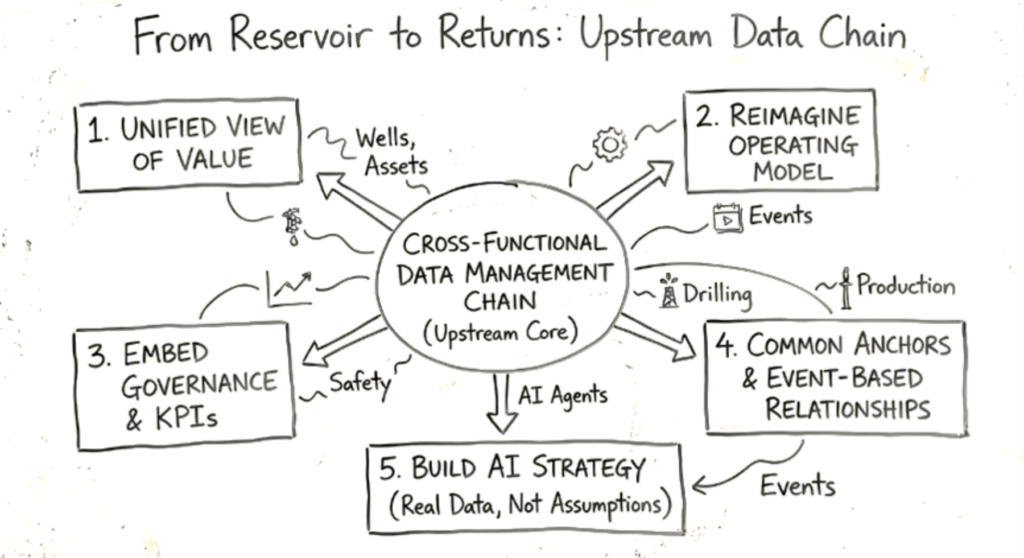
1. Rally the Organization Around a Unified View of Value
Teams will only embrace cross-functional data management when the enterprise value is explicit and tangible. That value must be articulated not as an abstract digital aspiration, but in measurable business terms:
- Capital efficiency driven by compressed planning cycles and improved portfolio choices
- Safety and reliability enabled by visibility from subsurface to facility
- Regulatory credibility through transparent and traceable information flows
- Financial uplift through better operational decisions supported by governed data
A unified data management foundation amplifies the organization’s ability to scale applied AI, turning AI from isolated experiments into systemic value creation, synchronizing the subsurface and surface lifecycle.
2. Reimagine the Operating Model, Not Just the Technology
In many companies, “data management” still equals “subsurface data” and is treated as an IT function. But modern upstream operations demand a holistic federated operating model, where IT provides the platform and guardrails, while the business provides the context and governance that spans the full value chain, from geological insight to fiscal measurement.
This requires elevating data governance to the functional and cross-functional levels, clearly defining interactions across drilling, production, facility operations, HSE, and engineering. Only then can the organization escape the gravitational pull of siloed legacy structures.
3. Embed Governance and KPIs that Reflect End‑to‑End Workflow Reality
Data governance must evolve beyond function-specific rules to reflect how decisions actually move across the business. Policies, standards, ownership models, lifecycle definitions, and KPIs must be designed with cross-functional use in mind.
A geological dataset that is “good enough” for exploration may be wholly insufficient, and even risky, for production engineering decisions. This is why upstream companies repeatedly experience operational surprises despite having “the data” somewhere.
4. Establish Common Anchors and Event-Based Data Relationships
Unification demands more than integrating tables. It requires defining the stitching elements – Wells, Formations, Assets, Equipment, Time (event & operational), and Location, that exist across every upstream function. Everything else hangs off these anchors. These anchors should leverage industry-standard frameworks (like OSDU) to ensure the stitching is interoperable across functions and tools.
Further, upstream data should be linked by events, not by the order of functions. For instance:
- Exploration data should influence drilling decisions.
- Formation stability insights should inform safety and environmental operations.
This event-based alignment turns static data into a coherent operational storyline. With a semantic layer that expresses business meaning, the organization finally achieves a trustworthy foundation for AI and ML.
5. Build AI Strategy on Real Data Characteristics and Physical Realities
What matters is matching data expectations to the nature of the decision. A common misconception in upstream digital programs is that every AI use case demands perfect data. In reality, different functions value different data characteristics, and fixation on uniform data quality often slows progress unnecessarily. Your two key actions remain critical to harmonizing these perspectives for hastening progress.
Your two key actions remain essential:
1.Classify AI use cases based on the data characteristics that truly matter. Some areas do require precision, such as drilling analytics, regulatory reporting or safety‑critical workflows. But many high‑impact functions benefit more from volume, variety, or velocity than from perfect accuracy. Reservoir characterization gains insight from large, noisy datasets; predictive maintenance relies on diverse signals; real‑time drilling optimization depends on fast data more than flawless data. For high-impact subsurface decisions, the data strategy must include physical (physics informed) constraints and domain expertise as part of the validation layer to prevent hallucinations that violate physical constraints.
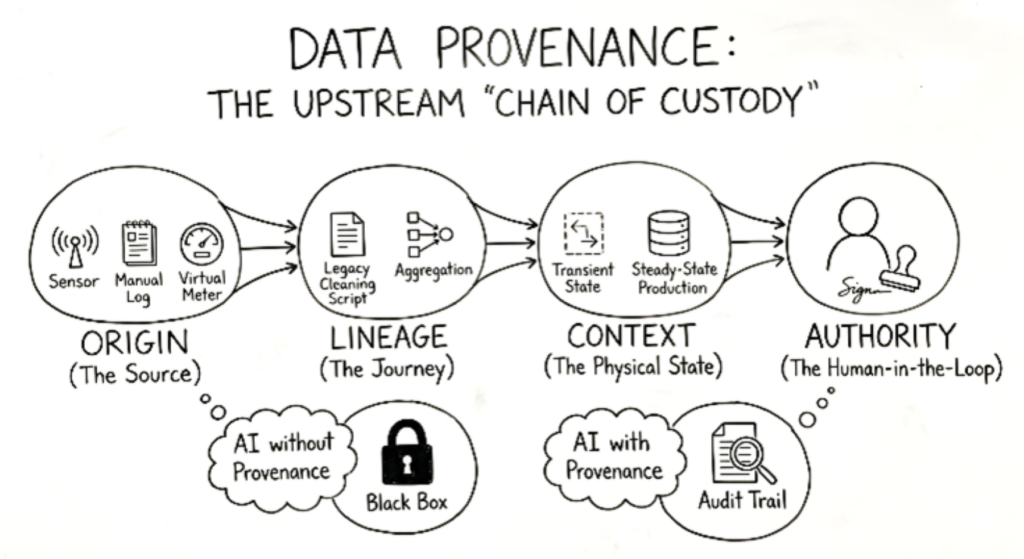
2. Integrate technology and data management at the enterprise level. This enables an AI workbench where business teams can work with diverse upstream datasets and experimenting quickly, but within a governed environment that respects functional needs without over‑engineering quality everywhere.
By shifting the question from “Is the data perfect?” to “What characteristics drive value for this workflow?”, organizations accelerate AI adoption where it matters most and reduce the friction between data, domain and technology teams.
Conclusion
AI is advancing faster than core oil and gas technologies. Over the next few years, we will see AI agents:
- Augmenting laborious data management tasks
- Generating operational and safety recommendations based on integrated subsurface‑to‑asset context
- Act as explainable AI co-pilots to perform end‑to‑end volumetric allocations with required accuracy
- Managing regulatory compliance workflows
- Integrating reservoir, production, and market data for commercial decision-making
None of this is possible without a unified, cross-functional data management foundation. Early movers, those who connect their data before deploying AI, will realize disproportionate value, faster and more sustainably.








