Last month, Windows systems around the world were rendered unusable due to a faulty update to CrowdStrike Falcon, an Endpoint Detection and Response (‘EDR’) solution used by many businesses worldwide.
This outage reportedly affected more than 8.5 million[1] CrowdStrike-enabled devices[2] around the world, causing them to crash with the infamous “Blue Screen of Death” (BSOD) and become stuck in a loop of endless reboots and further crashes. Major critical industries were among those affected, including banks, medical services and airlines, leading to grounded planes, closed businesses and massive financial costs estimated to be over $5 billion dollars[3].
Along with the financial damage, this has caused significant reputational damage to CrowdStrike as a well-known vendor of cybersecurity protection solutions[4].
Technical Details
CrowdStrike Falcon is a breach-prevention platform that leverages a unified set of cloud-delivered technologies which aim to prevent all types of attacks, such as malware.
Due to the proliferation of cybersecurity threats that target different kinds of organisations for financial and non-financial gain, the currency of EDR solutions is key. This means EDR solution providers have a competitive advantage where detection, containment, eradication and prevention of cybersecurity threats can be done as swiftly as possible.
As part of ongoing operations, CrowdStrike released a sensor configuration update[5] to Windows systems. Sensor configuration updates are an ongoing part of the protection mechanisms of the Falcon software. The sensor configuration update that was issued on 19th July 2024 triggered a logic error that led to subsequent system crashes, and in turn caused the Blue Screen of Death (‘BSOD’) on Windows systems that received the content update.
Solutions to De-Risk Application and Service Delivery
This point of view evaluates different solutions that can be implemented to ensure technology resiliency and business continuity considering the recent outage. Our perspective focuses on the entire lifecycle of the incident and outlines solutions that can be implemented before, during and after the incident.
Patch Management & Testing
Patch testing is a practice used to evaluate and validate software updates (patches, hotfixes, etc.) before deploying them to production systems. It ensures that patches do not introduce new issues or vulnerabilities, confirms that they function correctly within the destination environment, and validates that patches harmonise with other existing patches as well as new software candidates that are being considered for deployment.
The following diagram shows how patch management typically works. The key principle is progressing software release candidates into a Demilitarized Zone (‘DMZ’) for testing and evaluation to verify that the candidates work without creating adverse impacts to production environments.
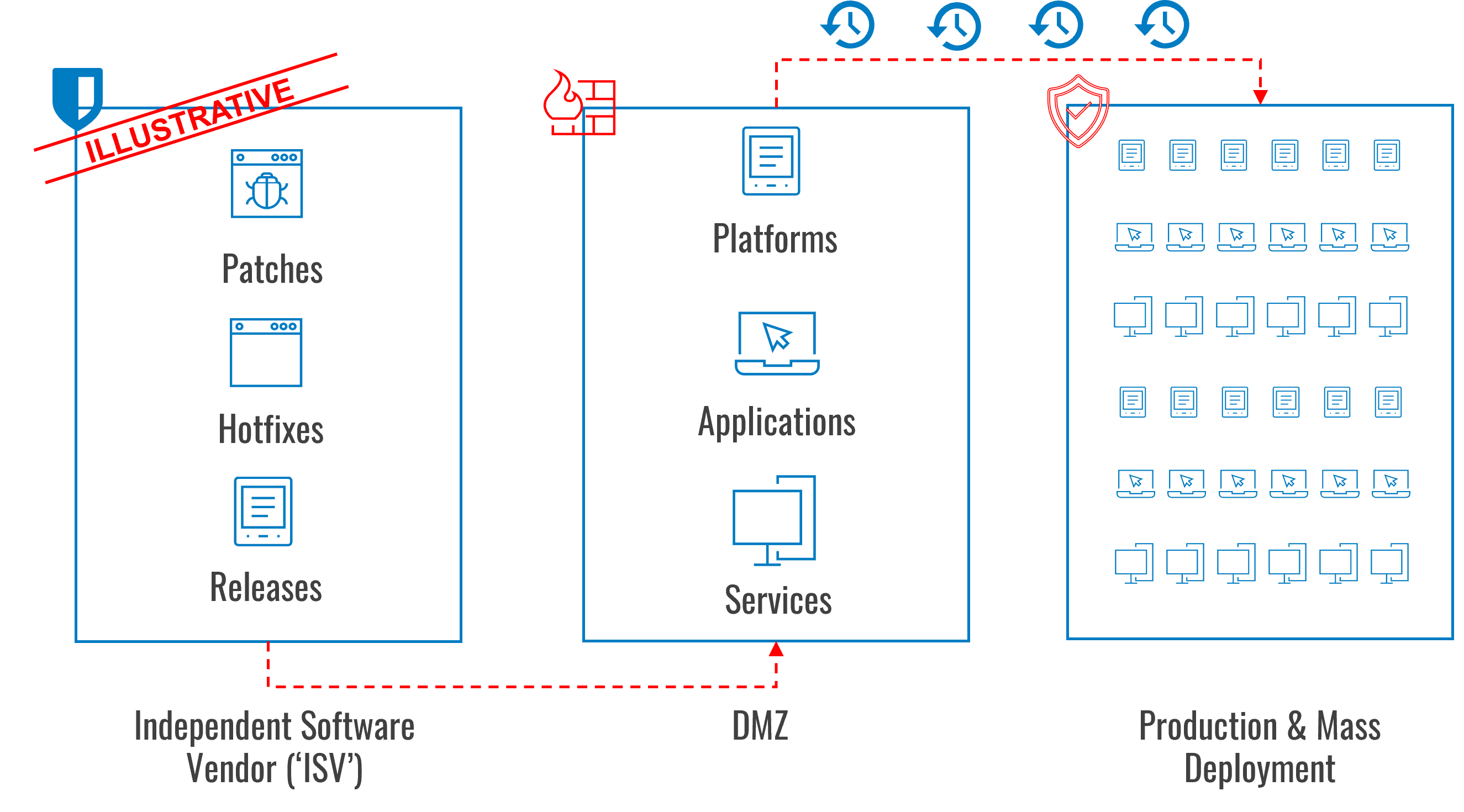
Depending on the type of environment, the criticality of assets being secured, and the software solutions being used to apply security, we recommend following a risk-weighted and process-driven approach when it comes to establishing a DMZ. This serves the purpose of simulating critical assets for testing purposes, where patches can be deployed and observed for any adverse impacts, i.e. regression testing. For an airline, these assets could represent self-check in terminals, or in the case of insurance companies, critical assets could be backend systems supporting batch processing.
The time allowed for testing can vary to ensure reasonable assurance and coverage of critical assets and other key software (e.g. applications that have direct kernel access to the underlying operating system, and therefore a significantly higher blast radius).
Based on the volume of software applications, systems and assets being tested, managing patch testing can become a highly complex exercise requiring a programmatic approach to acquiring, deploying, testing and certifying patches ahead of mass deployment. Introduction or uplift of existing release management capabilities would provide much-needed structure and governance of patch testing procedures.
We have outlined in the illustrative example below the type of information that would be required to maintain visibility across released patches. As the number of applications to test can increase exponentially, there is a requirement for a centralised platform to manage patch testing in enterprise environments.
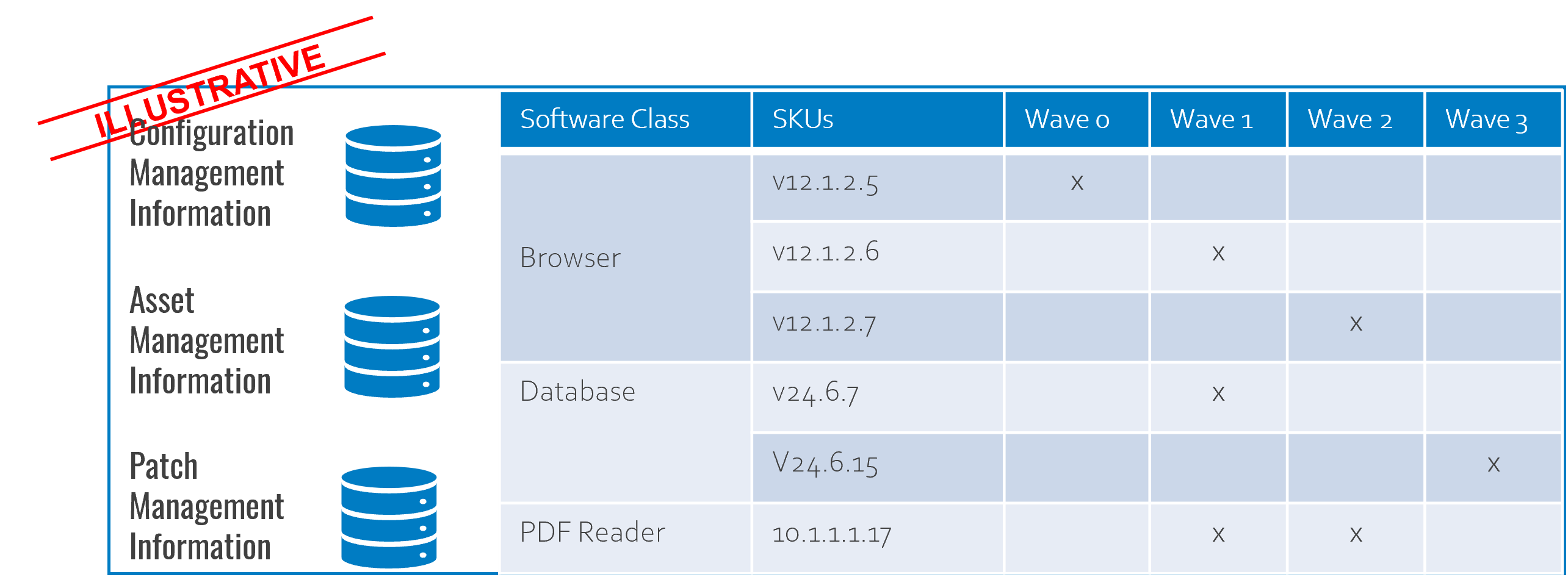
Patch testing is a meaningful solution for achieving reasonable assurance when introducing vendor-issued patches into a production environment, but it comes at a cost.
Whilst patches are deployed and tested in the DMZ, the so-called ‘soaking period’ (the time that is required to test patches and simulate as many probable production use cases as possible) slows down the velocity of introducing new functionality as well as maintaining security posture for existing applications. The soaking period can therefore vary between short to longer-term periods to ensure the right balance between timely software updates and reasonable assurance that the updates themselves are safe. In other words, the trade-off is between adverse impacts to time to market (‘TTM’) versus maintaining stability of mission-critical platforms.
Patch Deployment in Rings
Ring deployment is a practice that involves rolling out software updates gradually in groups (‘rings’) to an increasing number of users in production environments. The pattern incorporates feedback loops to ensure that software updates are deployed to the next Ring only after being applied successfully to the previous ring.
Additional possibilities are to structure the rings based on the criticality and impact of applications; for example, starting patch deployment with non-critical applications first (after testing in non-production environments). Each ring provides valuable feedback, allowing adjustments before the next iteration of deployment. These adjustments in turn increase reliability before full implementation is achieved. Ring deployment patterns start with the least critical assets and progress to the next level of criticality after successful implementation in the previous ring.
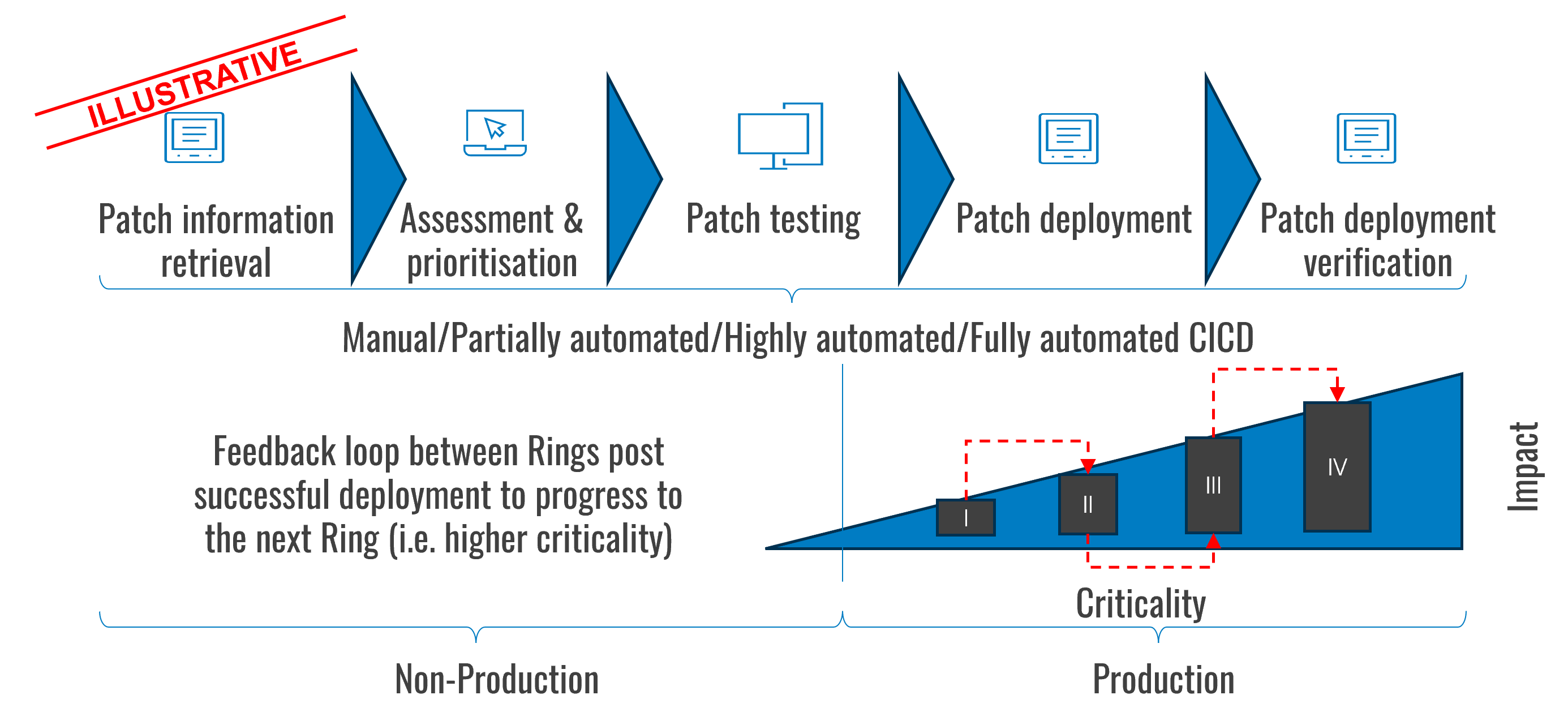
Whilst there are tools that support the deployment of patches in rings, this practice requires a strong emphasis on communication between users and a well-oiled service desk and incident management process.
Based on the type of organisation, rings can be structured to reflect different types of criticality. For example, rings can be organised by job functions with customer interactions, critical business functions, or they can be a representative sample of key users across different departments/business units. In other words, the pattern can be applied in a similar way to release channels in software engineering.
- I (Canary): This is the smallest group, often internal users or a subset of servers. It’s used to catch critical issues early.
- II (Early Adopters): A slightly larger group, including users who are willing to test new features.
- III (General Availability): The largest group, encompassing all remaining users.
- IV (General Availability): Production systems, platforms, namely enterprise servers and workloads.
Stress-testing Disaster Recovery to Decrease Recovery Timeframes
In instances where outages of critical applications and services occur, a robust recovery program is required to enable cybersecurity and technology resiliency.
A strong cybersecurity and technology resilience program revolves around a few critical elements:
- Prioritisation of applications and services based on criticality, e.g. Oxygen/Tier 0/1 (mission-critical), essential for core business functions, requiring immediate recovery.
- Defined recovery objectives and criticality considerations, such as recovery point objectives (‘RPO’), the maximum acceptable data loss (e.g., minutes for critical apps) and recovery time objectives (‘RTO’), as well as setting the maximum acceptable downtime (i.e. maximum acceptable time to restore systems and data).
- Defined procedures and methods to determine the work time recovery (‘WTR’), as well as a mechanism to ensure the period of testing integrity post recovery does not in itself create and bottlenecks as part of the overall recovery process.
Testing is required to ensure that probable scenarios are catered for and verified. In a highly connected digital ecosystem, this includes stress and disaster recovery testing of service providers and contractors, to ensure that outages that may be inherited from third parties are resolved and remediated in line with prescribed guidelines, e.g. outsourced services such as 24/7 monitoring, SaaS applications, telecommunication services, etc.
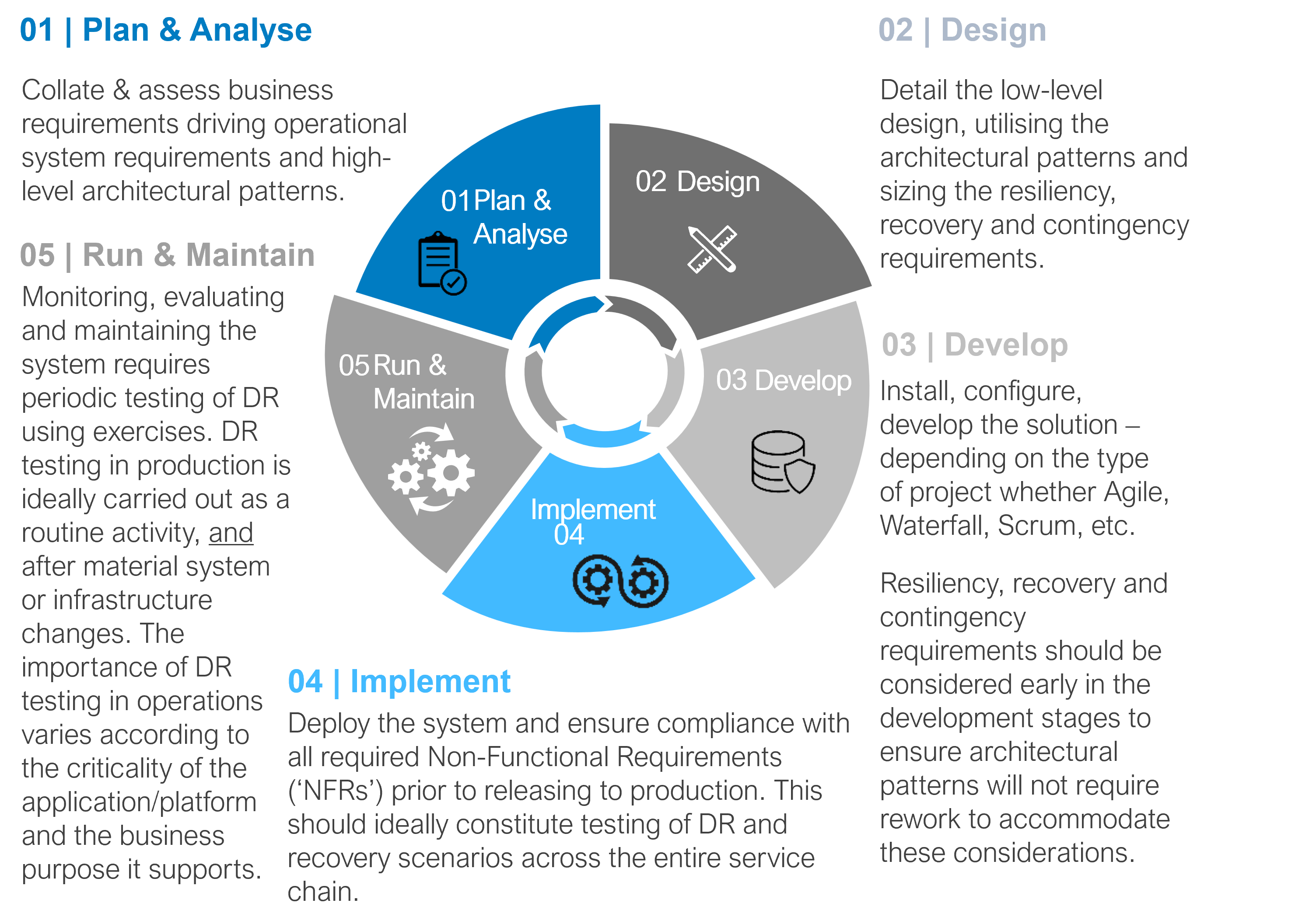
Further, disaster recovery testing needs to be incorporated into the entire system development life cycle (‘SDLC’). Periodic and thorough testing will ensure that procedures for recovery are adequately defined and tested, and therefore are reliable in expediting recovery.
By incorporating disaster recovery testing into the SDLC on an ongoing basis, enterprises can strengthen recovery procedures to the point where major incidents become just another test.
We have outlined the lifecycle of an incident to illustrate the interdependencies between recovery times and how this impacts the overall outage time.
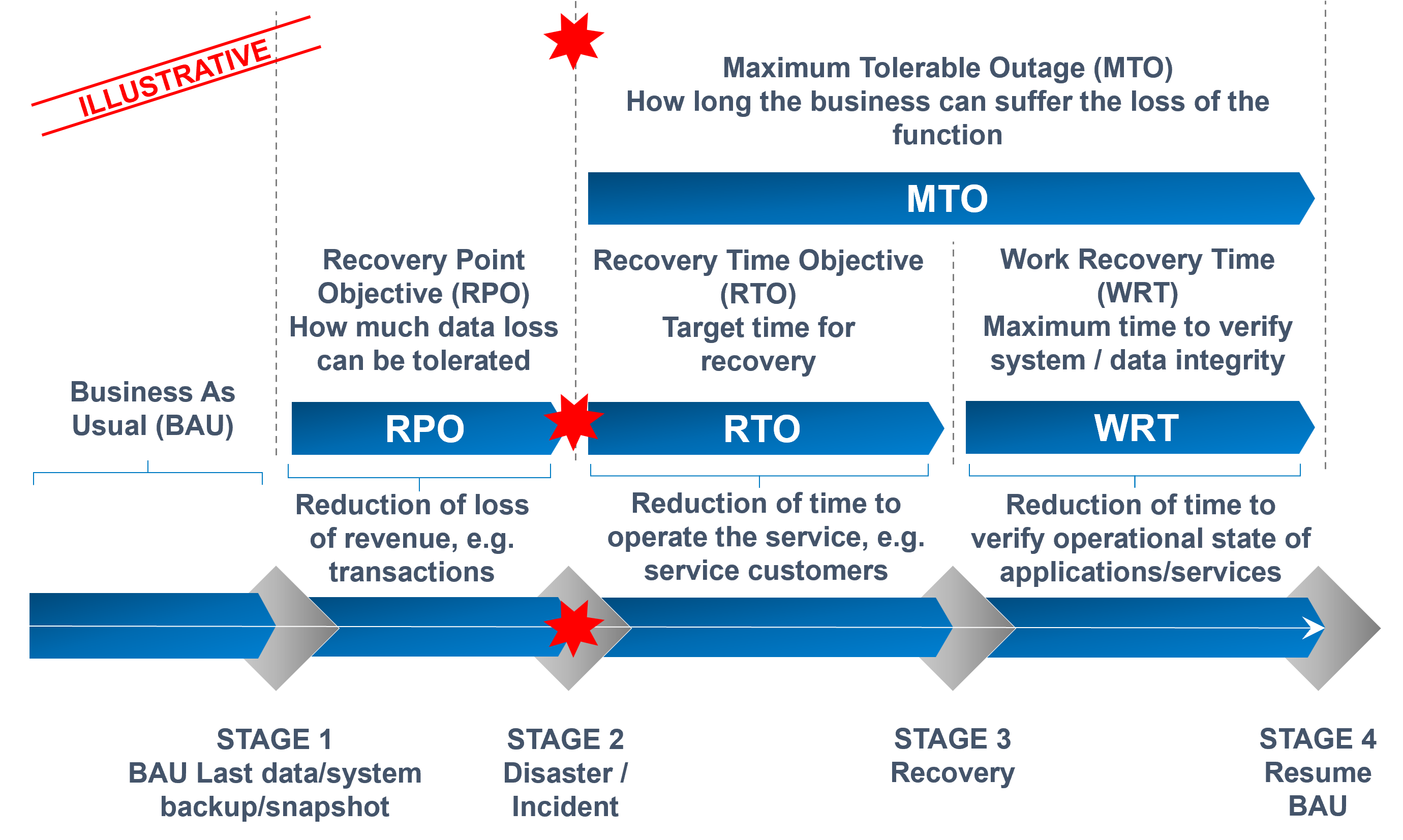
RPO and RTO need to be determined and specified for each critical business function and application. Times will differ based on business priorities and objectives determined through risk analysis. Defining RPO and RTO will help to drive the selection and implementation of adequate arrangements (e.g. resiliency, recovery and contingency patterns) for target applications.
A major challenge that organisations are struggling with is understanding the mapping between business processes, and technology services and applications. Mapping involves, in many instances, incorporating into the analysis any associated third party that is delivering or involved in delivering the service. Once this view has been established, determining the blast radius of a change as well as the actual impact of an unplanned outage becomes more accurate.
We have outlined the considerations for resiliency, recovery and contingency throughout the SDLC. This is to illustrate how a technology resiliency framework should support business and operational continuity throughout all stages of the software lifecycle; the concept being to ensure that the mean time to detect, respond and recover from an incident can be managed to meet business expectations. Techniques to align technology resilience with business expectations are plentiful and could include, for example, automated failover scenarios for applications once service levels are at risk of being breached.
Cloud Contingency Planning for Selected Business Functions
Additional patterns for contingency scenarios include fallback plans that rely on cloud services to ensure business and operational continuity. These can have a material impact during an unplanned outage: for example, the ability to use cloud-hosted desktop publishing applications through a browser, utilising data that is held securely in cloud storage, when a user’s company-issued laptop is no longer functioning.
This pattern is guided by the type of operations (e.g. most critical) and group of users that require contingency arrangements, e.g. frontline/client facing staff as well as senior management and governance functions (i.e. board, regulatory liaisons)
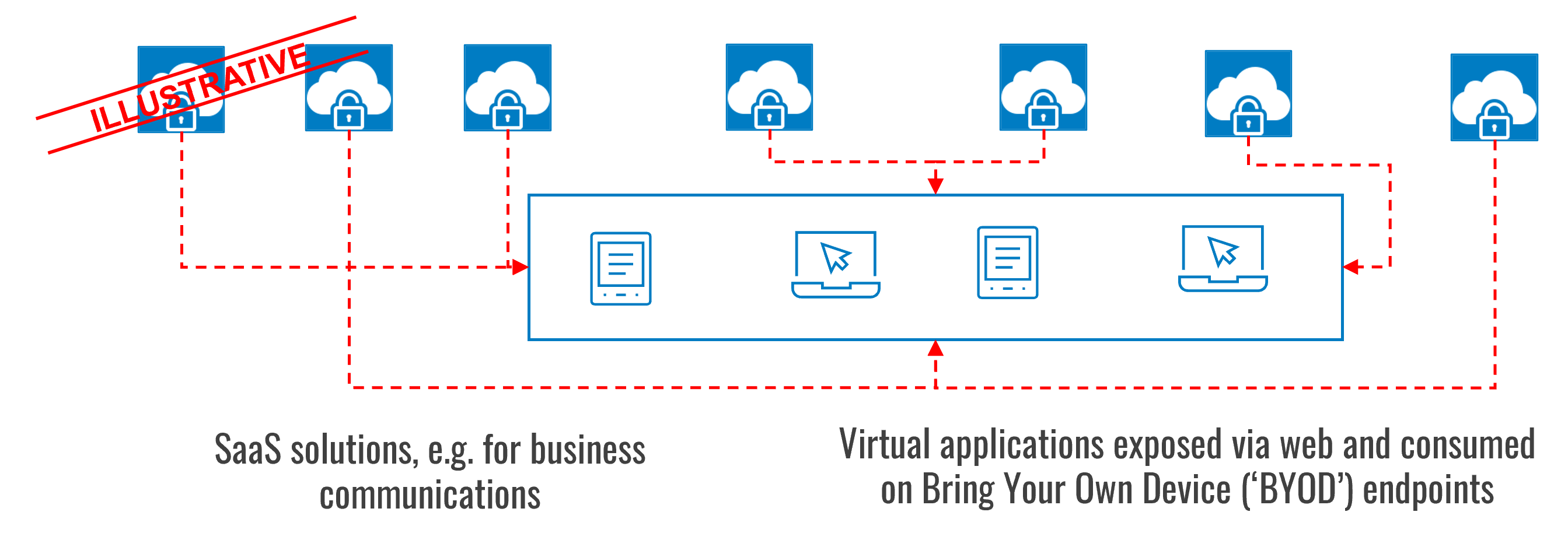
While the resilience pattern described above may be suitable to ensure short-term continuity of core services and functions, there are considerable limitations. For example, most users will be able to continue with their day-to-day operations, but other users would more likely experience downtime, such as software developers, graphic designers, and individuals requiring specialised computing infrastructure.
Further, in instances where support for BYOD devices is material, maintaining the confidentiality of information is a key risk that requires thoughtful consideration.
Nonetheless, using public clouds to provide some level of business continuity is a significant benefit over having no continuity at all.
Using Service Management Automation to support Risk Management Practices at Scale
Automation and Tooling to Manage and Drive Standards for Technology Operations
Modern corporate IT environments face challenges such as dynamic business requirements, technology changes, significant amounts of vendors and business partners, cloud services, compliance standards and other complexities that need to be managed on a constant basis.
Whilst this challenge is amplified for large organisations with an extensive geographical footprint, smaller organisations face the opposite problem – that is, IT assets may be limited, but so are the staff and resources required to carry out the necessary activities.
The solution for both large and small enterprises is tightly controlled and managed service management processes, encapsulated in tooling that is capable of programmatically applying standards and governance. This ensures that changes automatically conform with standards, such as approval processes, quality and gating criteria, as well as testing regimes.
For larger organisations in particular, service management automation is essential to manage an extensive resource base extending over thousands of endpoints, different standard operating environments (‘SOE’), and varied user platforms. IT staff can then be freed up to focus on higher value activities.
We have structured below key IT service management processes that support the prevention of, response to, and improvement of incidents in corporate IT environments. By integrating and automating these processes using appropriate service management tooling, enterprises can make patch testing and ring deployment practices scalable.
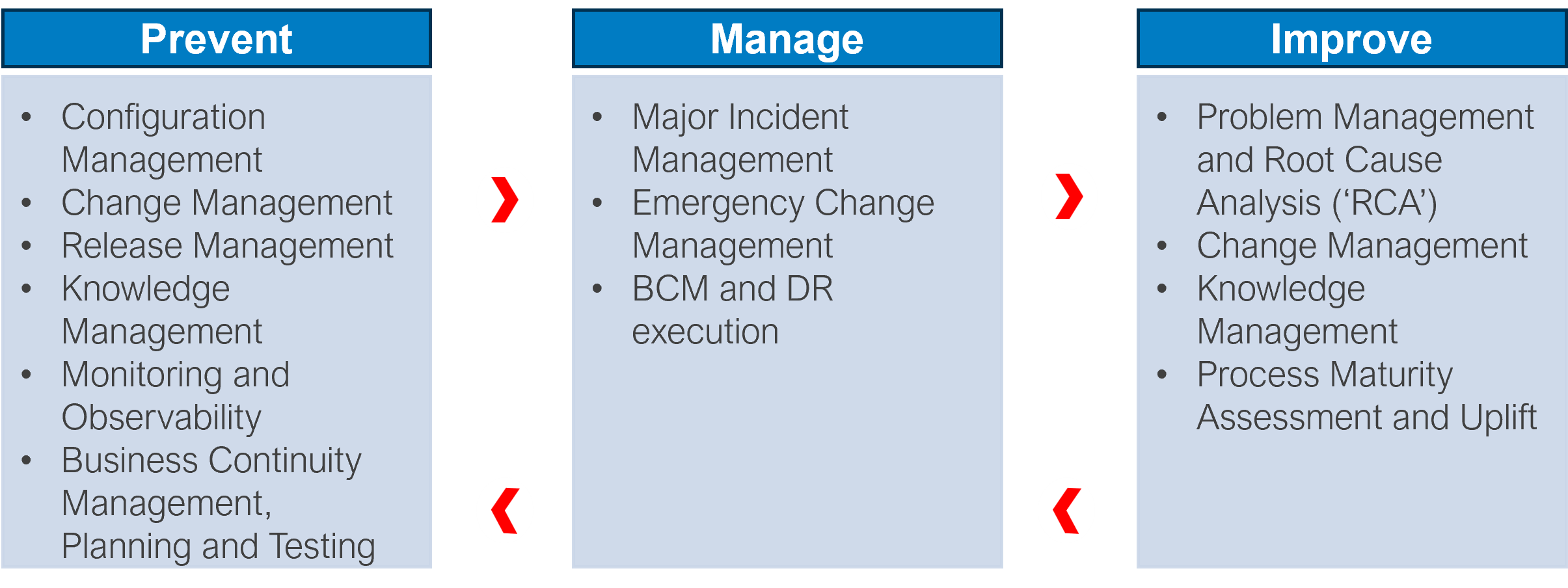
Two examples below illustrate the value of automation as well as streamlined, cohesive processes to manage technology currency in corporate IT environments. These examples apply to both small- and large-scale corporate IT environments.
Example 1 – Prevention of incidents by streamlining change planning through to service operations

Processes such as event management, incident management, change management, patch management, release management and rigorous testing are essential for a mature service delivery operation. These processes require integration all the way from change planning through to monitoring & observability. This integration can help by planning, managing and releasing changes to EDR solutions that can have the potential to adversely impact the endpoint fleet of an organisation.
Example 2 – Continuous service improvement by turning incident information into actionable intelligence and capability uplift

Whilst incidents are inevitable, effective response can minimize the impacts of unplanned outages. This includes being prepared for incident detection and service recovery. Being prepared requires assessing actual root causes as well as further refining or fine-tuning of response plans. For example, by identifying similarities in cases where a significant portion of incidents are attributed to the same infrastructure service, it is advisable to proactively define response plans and playbooks to expedite recovery of infrastructure services related to network, storage, identity, and so on.
Conclusion
ISV Due Diligence
Technology is ubiquitous – there is no point in denying it. The recent outage caused by CrowdStrike demonstrated that a regular update can, due to a series of unfortunate events, lead to an orchestrated (distributed) denial of service (‘DDoS’) and compromise both critical and non-critical infrastructure on a global scale.
While there has been reliance on vendor-issued patches for commercial off the shelf (‘COTS’) solutions and a dependence on vendors to perform diligent testing before deployment, the CrowdStrike outage has uncovered the reality that putting faith in ISVs alone to address the risks may itself be risky.
The CrowdStrike incident highlights the critical need for rigorous testing and validation of patches on the enterprise side before deployment. Organizations will likely adopt more stringent patch management practices in response, including staggered deployments and enhanced monitoring, to prevent similar issues from arising in the future. This will ensure that patches do not inadvertently cause disruptions, thereby maintaining system stability and security. Introducing a stage gate before releasing to production will, however, impact the currency and security of vendor-issued applications and services. Infosys’ contention is this trade-off is acceptable where there is an appropriate balance achieved between timely patching and business continuity, i.e. reasonable assurance.
Business Continuity
We have outlined a few patterns that can be implemented for organisations to maintain continuity of core business operations in similar circumstances to the CrowdStrike incident. Truth to be told, the incident represented a significant impact to certain industries around the globe (e.g. aviation and travel) and impacted the availability of critical information assets and services[6]. However, the magnitude of the outage’s impact went beyond ransomware infections we have witnessed in the past in terms of the sheer number of machines compromised[7]. An actual ransomware outbreak exploiting the same vulnerability could have materialised with significantly greater impact, leading to the loss of data as well as diminishing the availability of national critical infrastructure for a longer period.
While the solutions explored in this article have all their benefits, they also have drawbacks that need to be carefully evaluated on a case-by-case basis. Whether a solution is suitable depends on the organisation, its value chain, as well as the type of information asset that is in scope.
Reasonable Assurance vs Framework Compliance
Looking more closely into patch management and the testing of vendor-issued patching, there is an inherent benefit in obtaining reasonable assurance about software and applications that are introduced to an IT – and realistically OT – environment.
However, reasonable assurance impacts the release cycle and velocity of change, and to some extent the TTM, which is often a key performance indicator (‘KPI’) that business stakeholders use to measure the value that IT functions deliver. Additionally, introducing additional steps into the IT delivery process to maintain the currency and security of applications is antithetical with the perspective expressed in certain cybersecurity compliance frameworks, such as Essential 8. To reach the highest maturity level, two domains of the essential 8 cybersecurity framework require patching of applications and operating systems within 48 hours of a patch being deemed critical. This does not leave a lot of room for testing and rolling critical patches out in rings! But which approach is safer, given the global impact of the CrowdStrike outage: prioritising speed and framework compliance, or approaching technology risk with the lens of reasonable assurance? To answer the question, consider the consequences of the outage: at the time of writing, there are discussions happening about compensation from both the software vendor and cyber insurers1. Other adverse consequences, such as legal penalties, regulatory fines, and loss of customers, may flow to organisations that were impacted by the outage. The ramifications of this incident will likely keep surfacing for a prolonged period2, potentially creating unfavourable consequences for organizations that were left exposed.
While the CrowdStrike outage itself has caused significant adverse impacts in certain enterprises, there is an opportunity to treat this scenario as a dry run exercise for a major cybersecurity attack, which should in turn activate incident response procedures and contingency, resiliency and recovery protocols to ensure business continuity.
Key Takeaways
The questions every organisation that experienced a major incident should ask themselves now, after the fact, are:
- Has a post incident review (PIR) been conducted?
- What was the outcome of the PIR?
- How could this and similar major incidents be prevented in the future, leveraging some of the solutions as outlined in this PoV?3
[1] https://blogs.microsoft.com/blog/2024/07/20/helping-our-customers-through-the-crowdstrike-outage/
[2] https://www.microsoft.com/en-us/security/blog/2024/07/27/windows-security-best-practices-for-integrating-and-managing-security-tools/
[3] https://www.parametrixinsurance.com/in-the-news/crowdstrike-to-cost-fortune-500-5-4-billion
[4] https://www.investordaily.com.au/technology/55526-crowdstrike-fumble-bigger-than-just-reputational-damage-expert-warns
[5] https://www.scmagazine.com/news/crowdstrike-discloses-new-technical-details-behind-outage
[6] https://www.theguardian.com/technology/article/2024/jul/19/what-is-crowdstrike-microsoft-windows-outage
[7] https://www.kaspersky.com/resource-center/threats/ransomware-wannacry













