Inventory Management & Shelf Replenishment
Smart Inventory Monitoring, which involves detecting empty shelves and low stock conditions, poses unique challenges that need fine-tuning.

Why Fine-Tuning Was Necessary
- Complex Retail Environments:
Retail shelves are inherently dynamic. Variations in product arrangement, lighting, and camera angles can significantly impact detection accuracy. - Subtle Visual Differences:
The pre-trained model struggled to differentiate between intentional display gaps and genuine low-stock scenarios. This required the model to develop a more nuanced sensitivity. - Data Specificity:
Our retail data contains specific visual characteristics that weren’t fully captured in the general pre-training dataset, making domain-specific fine-tuning essential.
Fine-Tuning Methods for VILA
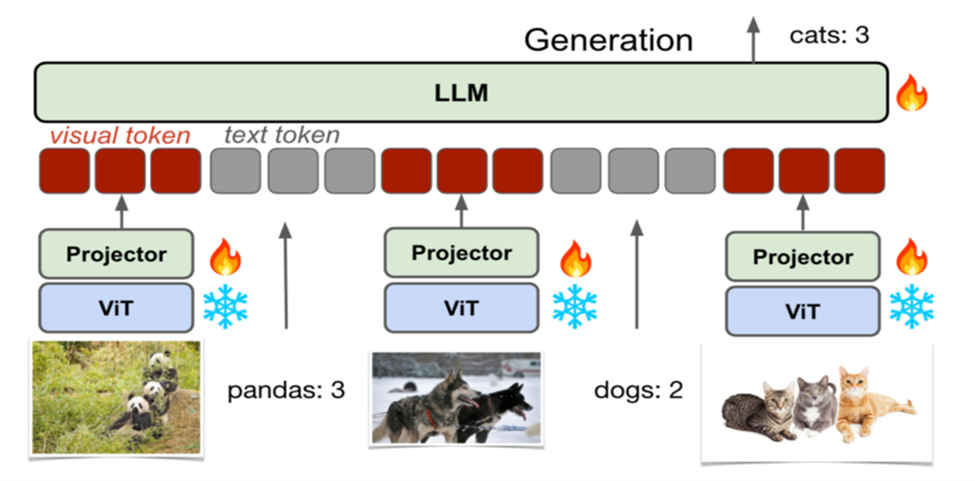
Architecture & Components
VILA employs an auto-regressive architecture that integrates visual and textual inputs seamlessly. Its design comprises three main components:
● Vision Encoder (ViT): Converts images into feature-rich embeddings.
● Projector: Bridges the visual encoder and the LLM by translating image embeddings into a tokenized format that the LLM can understand.
● Large Language Model (LLM): Processes both visual tokens and text, generating coherent, context-aware responses. This setup treats visual inputs like a “foreign language,” enabling the model to reason over multiple images and maintain strong text-only capabilities.
Fine-Tuning Methods and Observations
The table below summarizes the approaches, highlighting strengths and weaknesses:

Fine-Tuning Setup Using PEFT (ViT[1] [2] [3] [4] : FFT & LLM: LORA)
To enhance Smart Inventory Monitoring, we fine-tuned the VILA model using Parameter-Efficient Fine-Tuning (PEFT) method and applied full fine-tuning (FFT) on the vision encoder and LORA for the LLM . The pre-trained model initially misidentified empty spaces and low-stock areas, necessitating domain-specific adaptation.
Dataset
Videos Collected: 10 (8 for fine-tuning, 2 for testing) Camera Setup: Multiple sources focusing on a single shelf Preprocessing: ffmpeg re-encoding for compatibility Annotation Format: JSON (Segmented by events) Resolution: 2560x1440
Example Annotation:
{ "video_131_1": { "duration": 35, "subset": "training", "recipe_type": "131", "annotations": [ { "segment": [0, 5], "id": "1", "sentence": "Top rack: 4 Pepsi bottles, 2 orange bottles (low stock), etc." }, { "segment": [5, 8], "id": "2", "sentence": "Customer approaches the shelf." } ] } }
Training Setup
Model Fine-Tuned: VILA-1.5-34B GPUs: 8 x NVIDIA H100 (80GB) Batch Size: 8
Fine-Tuning Time
Total Training Time: ~2 hr 15mins Epochs Completed: 50
Prompt & Chunking Configuration
- VLM Dense Captioning Prompt:
Continuously analyze the video to create detailed captions that monitor the inventory levels across 5 racks on a retail shelf over time. For each rack, count the visible products and clearly distinguish between intentional design gaps and actual shortages. If any rack shows 2 or fewer products (ignoring the designated gaps), immediately mark it with a ‘Low Stock Alert’; if a rack has zero visible products, mark it with an ‘Empty Rack Alert’ also add a short description of the scene. Alerts generated should contains only brief details about the scene. Ensure that every detection event is accompanied by an accurate timestamp and that the status is updated dynamically as the video plays. Finally, compile these frame-by-frame insights dense caption that provides a comprehensive overview of the shelf’s status changes over time, highlighting the specific racks and moments when alerts were triggered. Format the final output for storage in a vector database for efficient retrieval and analysis
- Caption Summarization (LLM) Prompt:
Review the dense captions generated for the retail shelf, ensuring each event is tagged with precise timestamps. Extract and condense the key insights by focusing on the number of visible products per rack, the occurrence of ‘Low Stock Alert’ or ‘Out of Stock Alert’ events, and brief scene descriptions. Generate a succinct summary that highlights the critical inventory status, pinpointing the exact time and rack where stock issues were detected, to inform potential restocking actions efficiently
- Summary Aggregation (LLM) Prompt:
Combine multiple caption summaries, each with their associated timestamps, into a comprehensive overview that reflects the overall stock status across the retail shelves. Aggregate the individual insights to identify trends, such as recurring low stock or empty shelf events, over time. Provide an aggregated summary that highlights key products at risk, overall inventory health, and includes relevant timestamps for tracking changes and triggering timely interventions. Ensure the summary is actionable and clearly outlines areas requiring immediate attention.
- Video Chunking Strategy:
Chunk Size= 30secs
Results & Observations
We evaluated our approach on our dataset using two configurations: a Zero-Shot configuration, where the pre-trained VILA model is used without any fine-tuning, and a PEFT (ViT: FFT & LLM: LORA) configuration, where full fine-tuning is applied to the vision encoder component and the LLM is fine-tuned using Low-Rank Adaptation (LoRA).
Before fine-tuning, the zero-shot pre-trained VILA model frequently misidentified empty spaces as low-stock areas, resulting in inventory monitoring inaccuracies. However, after applying PEFT on VILA,[5] we observed significant improvements in product detection accuracy and fewer false alarms.
Performance Improvement
Zero-Shot Evaluation
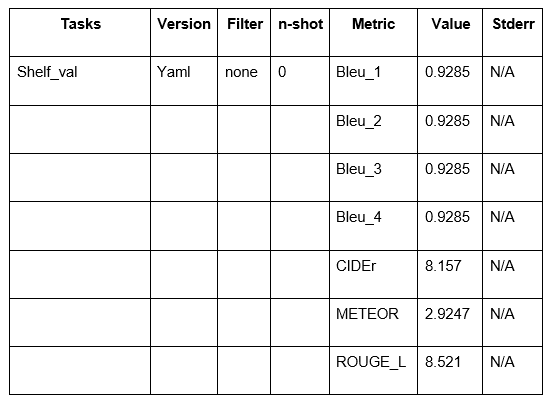
PEFT (ViT: FFT & LLM: LORA)

Key Observations
- Performance Boost: Fine-tuning more than doubled BLEU scores and significantly improved CIDEr, METEOR, and ROUGE_L, reflecting a notable enhancement in caption quality and alignment with ground truth.
- Efficiency with Limited Data: These improvements were achieved using a relatively small dataset and without full-scale fine-tuning, showcasing the effectiveness of our PEFT approach.
- Overall Impact: Our streamlined fine-tuning process significantly enhanced model accuracy and reliability in detecting low-stock conditions on retail shelves.
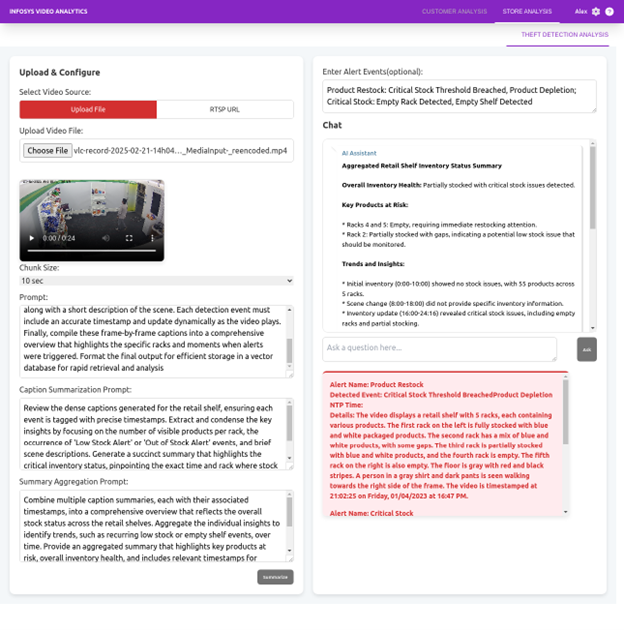
Sample Alert Triggered
Below is an alert generated when low stock or an empty shelf is detected:
Future Possibilities with Infosys Video AI Agent
Advanced Inventory Management
- Smart Reordering: Integrate with inventory systems to trigger automatic product reordering.
- Dynamic Shelf Management: Use real-time data to adjust shelf layouts dynamically.
Enhanced Customer Engagement
- Personalized Marketing: Leverage customer behavior analytics to deliver targeted offers.
- Augmented Reality (AR): Deploy AR interfaces for in-store staff, overlaying real-time VSS insights onto live feeds.
Continuous Learning & Adaptability
- Real-Time Fine-Tuning: Implement continuous fine-tuning to adapt to evolving retail scenarios.
- Customization: Tailor VSS for diverse retail settings, from small shops to large hypermarkets.
Conclusion
By combining advanced video analysis with intelligent summarization and real-time alerting, Infosys Video AI Agent redefines retail store monitoring. The integration of a Video AI Agent with fine-tuning techniques (like LoRA) has resulted in a system that not only improves security and safety but also optimizes inventory management and enhances customer satisfaction. As we continue refining our models and exploring new integrations, Infosys Video AI Agent is poised to set a new standard in AI-driven retail solutions.









