Introduction
The allure of Large Language Models (LLMs) in transforming enterprise workflows is undeniable. However, the path to successful deployment is fraught with complexities, particularly concerning licensing, data provenance, and model transparency. Before integration, a rigorous analysis of these factors is critical.
The Open-Source LLM Dilemma:
Enterprises exploring open-source LLMs face a unique set of challenges. Licensing terms demand meticulous scrutiny. Usage limitations on commercial use, redistribution, or derivative works (fine-tuning) necessitate careful evaluation, ensuring compliance with all licensing conditions. Furthermore, the model’s training data requires comprehensive assessment.
Data Provenance and Enterprise Fitment:
Evaluating the sources of the training dataset—be it public, proprietary, or web-based—is paramount. Legal, ethical, regulatory, and business concerns must be identified and mitigated. A critical step is ensuring the model’s training data aligns with domain-specific enterprise requirements. Gaps that impact performance in critical workflows must be identified, necessitating fine-tuning or adaptation to meet business objectives.
The Case for Specialized Efficiency: Small Language Models (SLMs)
While LLMs offer broad capabilities, their sheer size and computational demands can present significant barriers to enterprise adoption, particularly in resource-constrained and data sensitive environments. This is where Small Language Models (SLMs) emerge as a compelling alternative. SLMs, designed for specific tasks and domains, offer a path to optimized performance and efficiency.
Leveraging accelerated computing, such as NVIDIA H100 Tensor Core GPU, can further enhance the performance and efficiency of SLMs at a much lower cost. NVIDIA NIM™ microservices provide comprehensive tools and libraries for optimizing SLM deployment, enabling enterprises to unlock the full potential of these.
Approach
Enterprises often find LLMs inefficient for specialized use cases due to their broad training data and high computational costs. In contrast, Small Language Models (SLMs) offer a domain-specific alternative, delivering comparable or superior performance with reduced resource requirements.
To address enterprise needs, we developed a foundational SLM, leveraging curated datasets in compliance with organization data policies.
Due to high regulatory, data privacy and sensitivity needs, we chose banking and IT Ops as two domains for developing a specialized SLMs. The specialized variants of this foundational SLM led to development of Infosys Topaz BankingSLM for financial domain and Infosys Topaz ITOPsSLM for IT Operations domain.
Infosys Topaz BankingSML – is a specialized SLM for supporting various knowledge management activities and it also supports powering two powerful assistants SupportPro and KnowledgePro, that help various personas in the organization to enhance the knowledge and experience around banking and Infosys Finacle, an industry leading digital banking solution.
Additionally, SLM for cyber security and Infosys Topaz ITOPsSLM are being fine-tuned for various use-cases around cyber security, knowledge management, log analysis.[AS1]
Having a strong foundational model allows to extend these models for other specialized domains and relatively smaller compute
Data Gathering and Pre-processing using NVIDIA NeMo Curator
The dataset development process focused on collecting high-quality, domain-relevant data while adhering to Responsible AI practices and licensing guidelines. The dataset primarily consists of English content, with substantial multilingual, code, and math-related data, along with a portion of Infosys proprietary data for specific versions of enterprise SLMs.
Our proprietary dataset included approximately 2 TB of PDFs, HTMLs, knowledge articles, product support tickets we wrote pipeline to parse PDF and HTML and rewrite to improve the quality of parse text and maintaining semantic structure of the original documents. We used NVIDIA NeMo™ Curator to remove sensitive information like PII data, usernames, IP addresses etc.
Data filtering and qualitative pre-processing were carried out using the NeMo Curator tool for deduplication, domain classifier models for quality assessment, and data blending for refinement. To address domain-specific data limitations, synthetic data generation was employed.
We used about significant datasets with the mix of English, Spanish, Hindi, French and mix of programming languages and Math datasets.
We used publicly available, permissive licensed language and code datasets with carefully extracting high quality tokens using NeMo Curator pipelines for:
- Classifying high quality tokens from the existing corpus of downloaded data
- Classifying domain specific tokens, over and above token sourced from publicly available financial sources
- The entire process was run on H100 GPU Cluster using Dask based jobs to curate the training data
Below diagram shows the entire end-to-end process for data curation and model training.
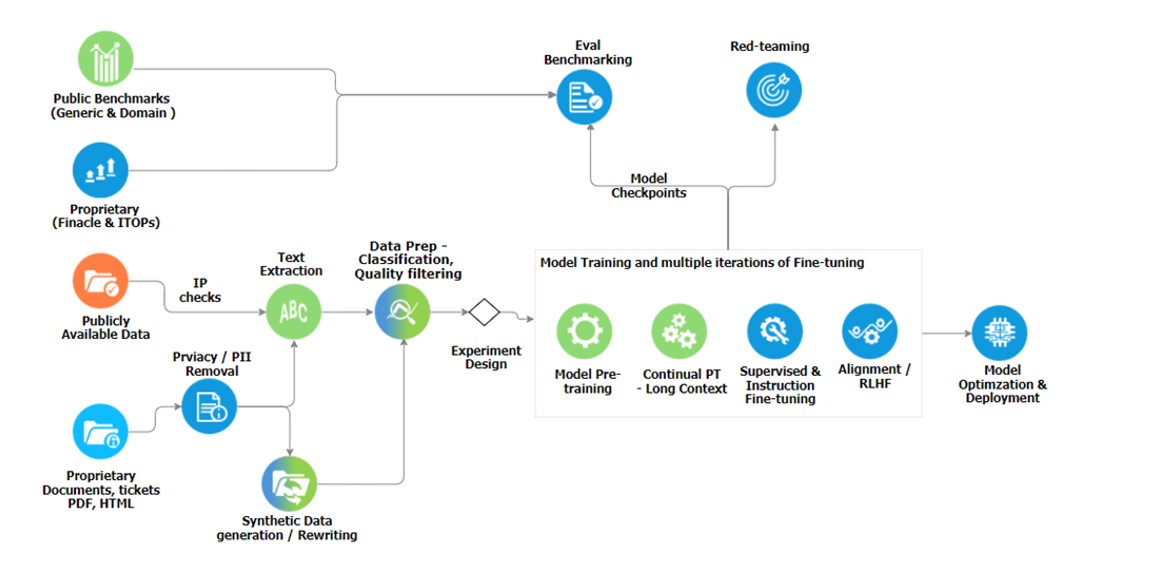
Synthetic Data Generation and Styling Using LLMs
We used innovative approaches like Magpie to synthesize high-quality data for Finance without relying on prompt engineering at scale, ensuring alignment with enterprise needs
The generated synthetic data underwent rigorous filtering and quality checks, resulting in a robust dataset for training foundation models.
For our proprietary datasets, we up-sampled the original dataset to enhance the quality of the tokens from the sources like ticket data and rewrote some of the documents by using persona styling.
We used large language models along with Ray + NVIDIA TensorRT-LLM for generating the tokens at scale in large distributed cluster.
Model Training Using NVIDIA Nemotron Framework
Our model training follows an autoregressive language modeling approach with an 8k context length, leveraging Flash Attention for efficiency.
Training was conducted on a distributed multi-GPU setup with mixed-precision training and regular checkpoints for optimization using NVIDIA Llama Nemotron framework.
We followed multi-step pre-training and fine-tuning approaches in 3 phases:
- Pretraining, which established a broad foundational model using diverse data, initial context length was kept at 8k.
We ran the pre-training for single epoch of data,
- Long Context extension was applied to improve the model’s ability to handle extended inputs, ensuring better coherence and relevance for enterprise applications. We extend our context length to 32k
- Continual Domain Pretraining, where we introduce domain specific data to create a domain specific variant like BankingSLM and ITOpsSLM
For each stage of continual pre-training we used standard continual pre-training recipes, and long-context and domain specific data mixed with a small portion of pretraining data used earlier.
Evaluations and Results
We developed an extensive evaluation harness based on lm-eval to thoroughly test our model against various open-sourced models available with permissible license:
- Open-sourced language benchmarks
- Code benchmarks
- Non-English Language benchmarks
- Long-context benchmarks
- Banking & financial domain specific benchmarks
- Infosys proprietary benchmarks targeted towards our product and platforms.
We conducted a total of 65 benchmarks, on 11 different metrics including techniques are like LLM-as-a-judge to evaluate clarify, completeness, correctness and relevance.
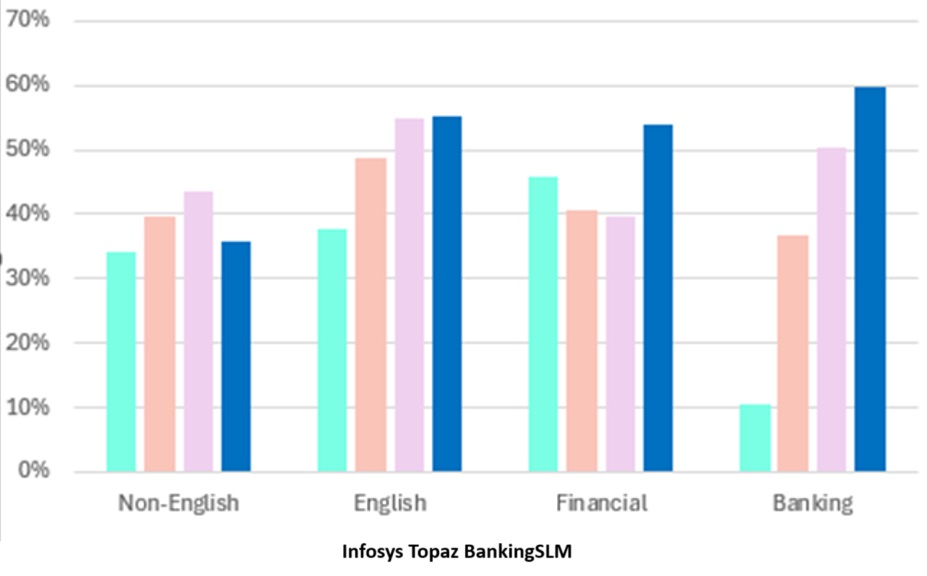
Above is an average accuracy across all languages and domains specific benchmarks, other bar represents similar sized open-sourced models.
Here are our overall observations and learnings:
- Our SLM out-performed publicly available open-sourced similar sized models in domain specific benchmarks and on other benchmarks it does comparably well.
- Continual pre-training is helpful in improving the domain understanding of base model
- For documents like PDFs, it is important to preserve the layout information using vision-based techniques, as well as processing those documents at scale requires GPU based solutions. NVIDIA NIM along with Ray scales linearly for large workloads.
- We are working on optimizing the SLM for inferencing needs, in order to reduce the resource utilization and making sure that it is available at fraction of GPU capacity
Conclusion
As enterprises navigate the complexities of LLM adoption, the strategic implementation of SLMs offers a pathway to efficient, targeted AI solutions.
By carefully evaluating licensing, data provenance, and model fitment, and by embracing the specialized efficiency of SLMs, businesses can unlock the transformative power of AI while optimizing resource utilization.








