Cybersecurity demands a proactive approach, going beyond simply reacting to threats. It demands proactive, intelligent systems capable of learning from every interaction. Enter Small Language Models (SLMs), fine-tuned for specific domains like cyber defense. These models, when continuously updated, can transform from static tools into dynamic assets that adapt to emerging threats.
In our previous blog, we explored how fine-tuning LLaMA models enables the creation of cybersecurity-specific chatbots and agentic AI systems. Building upon that foundation, this post takes a step further—toward enabling these models to learn from their own mistakes.
The true potential of SLMs is unlocked when they can learn from user interactions, particularly from instances where their responses fall short. By capturing signals of dissatisfaction—such as follow-up questions indicating confusion or frustration—we can create a feedback loop that drives continuous improvement. This approach ensures that the model not only provides accurate information but also aligns with the user’s expectations and needs.
Large Language Models (LLMs), like GPT-4, offer a unique opportunity to enhance this process. Their generative capabilities can be harnessed to augment training data, creating new question-answer pairs that address gaps identified through user feedback. This synergy between SLMs and LLMs fosters a self-learning memory system, enabling cybersecurity models to evolve in real-time, much like a seasoned analyst refining their expertise with each new challenge.
In this blog, we will explore how to build such a self-learning memory for SLMs from a cybersecurity perspective. We will delve into the steps of capturing user dissatisfaction, suppressing sensitive information, generating enhanced training data, and fine-tuning models to create a continuous learning loop. By the end, you’ll have a comprehensive understanding of how to transform your SLM into a self-improving cybersecurity assistant.
When to Use Fine-Tuning vs Retrieval Augmentation (RAG) in Cybersecurity
Choosing between fine-tuning a Small Language Model (SLM) and using Retrieval-Augmented Generation (RAG) depends heavily on the cybersecurity use case and the nature of the data involved.
Fine-Tuning: Embedding Domain Expertise Deeply
Fine-tuning updates the model’s internal weights to incorporate new knowledge, making it an excellent choice when you need the model to intrinsically understand evolving cyber defense tactics, attacker behaviors, and threat intelligence. For example, if a SOC analyst notices recurring patterns of novel phishing attacks or new malware behaviors, fine-tuning the SLM with these examples ensures the model inherently grasps these subtleties and can respond accurately without external context.
Fine-tuning is best when:
- The knowledge updates are structured and stable over time.
- You want consistent, fast responses without relying on external document retrieval.
- The use case demands deep domain reasoning that benefits from the model’s latent understanding.
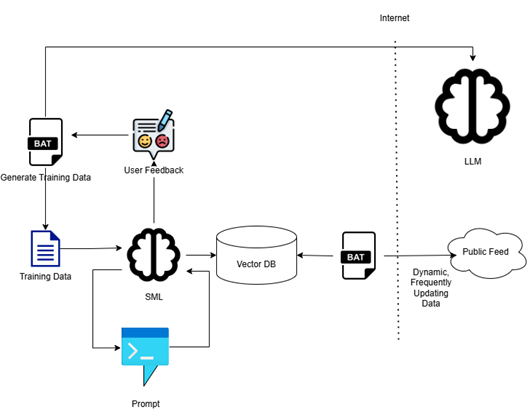
Retrieval Augmentation (RAG): Leveraging Dynamic, Growing Corpora
RAG combines a fixed language model with a retrieval system that pulls in relevant external documents or data at query time. This approach is ideal when the knowledge base is rapidly changing, such as newly released threat reports, vulnerability disclosures, or real-time incident logs.
RAG is preferred when:
- The corpus is large, dynamic, and frequently updated.
- You want to maintain a lightweight core model without constant retraining.
Responses must incorporate the latest information that may not yet be part of the model’s training.
Prompt Tuning: Lightweight Adaptation for Rapid Adjustments
Prompt tuning (also known as instruction tuning or prefix tuning) enables targeted behavioural changes in Small Language Models without modifying their core weights. Instead of retraining the entire model, prompt tuning appends learnable embeddings or text prompts that guide the model’s output in a specific domain or context.
This approach is especially effective in cybersecurity scenarios where:
- The team wants rapid updates without large compute resources.
- The model is hosted in a restricted environment (e.g., on-prem SOC, air-gapped systems).
- You want to experiment with user-intent shifts or temporary guidance without committing to full fine-tuning.
For instance, a model can be prompt-tuned to prioritize threat intelligence from a particular vendor or emphasize a zero-trust policy context across all interactions.
Prompt tuning is best when:
- You need fast, low-cost iteration over behavior.
- You are experimenting with A/B testing new model styles or tones.
- Infrastructure limitations restrict model retraining.
Cybersecurity Example
Consider a scenario where a SOC chatbot supports analysts by answering questions about attacker Tactics, Techniques, and Procedures (TTPs):
- If new TTPs emerge and need to be embedded into the chatbot’s core knowledge, fine-tuning the SLM ensures the model can reason and generalize about these tactics seamlessly.
- However, if analysts need quick access to the latest threat intelligence reports or incident data, a RAG approach allows the chatbot to pull in up-to-date documents without retraining.
In practice, many cybersecurity solutions combine both—using RAG for fresh data and fine-tuning for stable core knowledge. This blog focuses on advancing the fine-tuning side by building a self-learning memory that continually updates the SLM based on user feedback and dissatisfaction signals.
Steps to Create Long Term Memory
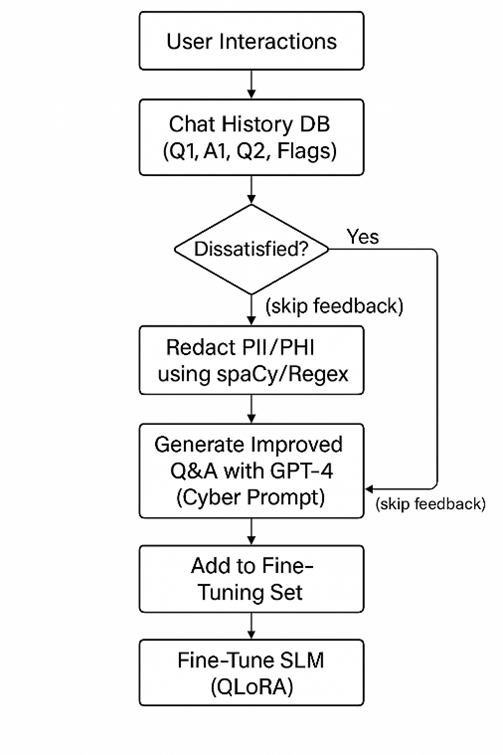
Step 1: Building the Fine-Tuning Pipeline for Cyber SLMs
To enable a Small Language Model (SLM) to learn continuously from user interactions, we need a modular, auditable, and secure fine-tuning pipeline. The goal is to create a loop where model performance improves based on real-world chat data—particularly on questions that expose limitations in the model’s current knowledge.
Key Components of the Pipeline:
- Chat Interaction Capture: Capture question-answer pairs from end-user interactions, especially focusing on cases where follow-up questions indicate confusion or dissatisfaction.
- Dissatisfaction Detection: Use sentiment analysis and heuristics to identify follow-up questions that imply the previous response was unsatisfactory.
- Sensitive Data Redaction: Automatically scrub personally identifiable information (PII), such as emails, IP addresses, names, and organization details, to ensure compliance and data safety.
- Augmented Data Generation: Use a secure GPT-4 API backend to create improved or alternate Q&A pairs, based on the gaps identified.
- Dataset Curation & Formatting: Structure the collected and cleaned data into instruction-tuning format (e.g., Alpaca-style) for ingestion.
- Model Fine-Tuning: Use QLoRA or LoRA-based adapters on top of the LLaMA 3.1 8B base model to reduce compute requirements while achieving high adaptability.
- Benchmark & Feedback Loop: After fine-tuning, evaluate the model on both known and new queries to validate learning improvement.
Step 2: Logging User Conversations in a Relational Database
Capturing real-world interactions between users and your cyber defense chatbot is the foundation of a self-learning system. However, instead of logging entire session histories or user identifiers, the focus should remain on contextually meaningful Q&A pairs—especially those where a user’s next question reveals ambiguity, confusion, or dissatisfaction with the previous answer.
What to Log (Minimalist Schema):
| Column | Type | Description |
| question | TEXT | The user’s input query (q1) |
| answer | TEXT | The model’s original response (a1) |
| next_question | TEXT | The follow-up question (q2 or qs) |
| sentiment | FLOAT | Sentiment score of next_question (computed later) |
| flagged | BOOLEAN | Whether the conversation should be considered for retraining |
This simple schema, stored in a Relational database, is optimized for identifying improvement areas without compromising user identity.
Example Conversation:
- q1: “How does lateral movement work in APT attacks?”
- a1: “Lateral movement allows attackers to move across systems after initial compromise.”
- qs: “Can you give an example in a Windows Active Directory environment?”
- Sentiment score: -0.3
- Flagged: ✅
Even though a1 isn’t technically wrong, qs clearly indicates that the answer lacked context or clarity for the user’s specific need. This pair is ideal for re-training.
Step 3: Capturing User Dissatisfaction Through Sentiment Analysis
Not all user follow-up questions indicate dissatisfaction—but when they do, it’s a critical signal for improving the model. Sentiment analysis helps us identify these moments automatically and at scale. In the context of cybersecurity chatbots, we’re especially interested in detecting:
- Confusion (“What do you mean by…”)
- Frustration (“That’s not helpful, explain more.”)
- Ambiguity requests (“In which scenario would that apply?”)
While sentiment analysis is typically used in customer experience contexts, it can be adapted for technical domains using open-source libraries.
Open-Source Options
We’ll use Valence Aware Dictionary, for sentiment Reasoning (VADER), is a lexicon-based sentiment analyzer that works well even with follow-up questions. It’s lightweight, fast, and license friendly. You can also extend this later with Hugging Face models or LLM-assisted critique.
Python Code Snippet: Sentiment Scoring
Ref :
Sample Output:
Sentiment Score: 0.05, Flagged: True
NOTE: Over time, you can evolve this logic into a hybrid model using LLMs to classify user follow-ups as “unclear/neutral/clear”, allowing more nuanced scoring.
Step 4: Suppressing Sensitive Information in Q&A Data
Before using chat transcripts for fine-tuning, it’s essential to remove or anonymize any personally identifiable information (PII) or sensitive organizational data. This is not only a security best practice—it also helps ensure compliance with data protection standards like GDPR and enterprise policies.
In cybersecurity chats, the typical sensitive entities to redact include:
- Usernames, names of individuals
- Email addresses
- IP addresses (v4 and v6)
- Organization or domain names
- File paths, registry keys
- Internal project or tool names
Python Code Snippet: Suppressing Sensitive Information
Ref
- https://spacy.io/usage/rule-based-matching
Example
sample_qa = """
User abc@xyz.com reported suspicious behavior from 192.168.1.12.
Tool 'NetScanPro.exe' found anomalies on C:\ \Program Files\ \NetScanPro\ \run.exe.
Escalated to Alice from Infosys Security Response.
"""
Step 5: Generating Better Training Data Using GPT-4
Once you’ve identified unsatisfactory Q&A pairs and redacted sensitive data, the next step is to generate improved responses—or entirely new, well-formed training samples. For this, you can leverage GPT-4 via Azure OpenAI, configured with appropriate prompt engineering to stay within the cyber defense domain.
This process allows your self-learning memory system to bootstrap better responses using a high-performing LLM before retraining your fine-tuned LLaMA 3.1 model.
Prompt Design: GPT-4 for Cybersecurity Q&A Improvement
We craft a task-specific prompt that:
- Describes the chatbot’s role
- Provides the original question and sub-par answer
- Requests an improved, red-team/blue-team aware response
- Optionally, asks for 1–2 synthetic variations for robustness
Sample Prompt
Format:
Step 6: Fine-Tuning the Model (LLaMA 3.1 8B)
Now that we’ve captured dissatisfaction signals, redacted sensitive data, and enriched the training set using GPT-4, it’s time to fine-tune your Small Language Model (SLM)—LLaMA 3.1 8B—to better respond in cybersecurity contexts.
Because full fine-tuning of an 8B model is compute-intensive, we recommend using QLoRA (Quantized Low-Rank Adaptation) or LoRA, which enables parameter-efficient tuning by injecting lightweight adapters into selected layers.
Model Architecture and Training Strategy
- Base Model: meta-llama/Llama-3-8B
- Technique: QLoRA (recommended) or LoRA
Step 7: Testing and Benchmarking the Fine-Tuned Cyber Model
Fine-tuning is only useful when it leads to measurable improvement. To validate the effectiveness of your enhanced LLaMA 3.1 8B model, it’s important to define metrics, collect test data, and compare results against baselines (e.g., the base model or GPT-4 outputs).
Evaluation Strategy
You can use a mix of automatic and manual methods:
| Evaluation Type | Approach | Tools |
| Accuracy / Correctness | TEXT | The user’s input query (q1) |
| Helpfulness / Clarity | TEXT | The model’s original response (a1) |
| Response Diversity | TEXT | The follow-up question (q2 or qs) |
| Token-Level Metrics | FLOAT | Sentiment score of next_question (computed later) |
Sample Test Questions
| Question | Expected Trait |
| “How can I detect Kerberoasting?” | Technical depth |
| “What does the MITRE T1548 technique involve?” | Correct classification |
| “Explain persistence mechanisms in Linux.” | System-specific clarity |
| “Why is DNS tunneling dangerous?” | Conceptual precision |
Python Snippet: GPT-4 as Judge
Here’s a quick tool to score responses using GPT-4 as a judge (yes, your model can now be critiqued by GPT-4 itself):
Prompt:
system_prompt = (
"You are a cybersecurity expert and evaluator. Score the candidate response for its technical accuracy, clarity, and usefulness "
"on a scale of 1 to 10. Explain the rating briefly."
)
user_prompt = f"""
Question: {question}
Reference Answer: {reference_answer}
Candidate Answer: {candidate_answer}
Score the candidate out of 10 and provide reasoning.
"""
Python Snippet: BLEU / ROUGE
Ref:
- understanding-bleu-and-rouge-score-for-nlp-evaluation
- understanding-bleu-and-rouge-score-for-nlp-evaluation-1ab334ecadcb
Tips for Cyber Evaluations
- Evaluate per MITRE tactic (e.g., Discovery, Lateral Movement) for targeted fine-tuning impact.
- Include new synthetic questions to check generalization.
- Track follow-up satisfaction signals again post-deployment for feedback loop validation.
Conclusion: Toward Continual Learning in Cyber Defense AI
In today’s rapidly evolving threat landscape, a static cybersecurity assistant is quickly outpaced by attacker innovation. This is where self-learning memory becomes transformative. By capturing dissatisfaction signals from real user interactions, redacting sensitive content, and generating better training samples with GPT-4, we unlock a sustainable path for improving Small Language Models (SLMs) like LLaMA 3.1 8B.
This feedback-driven architecture enables a closed-loop system that fine-tunes itself over time—learning from missed context, ambiguous responses, and edge-case scenarios. By augmenting traditional datasets with real-world usage and failure patterns, we build more resilient, context-aware, and cost-efficient cyber defenders.
Fine-tuning is not a silver bullet. It complements but does not replace retrieval-based architectures like RAG. Together, they form a continuum—from long-term memory to dynamic context grounding. Organizations can strategically adopt both, guided by operational needs, latency budgets, and model governance policies.
As the cyber domain becomes increasingly agentic, enabling our models to learn from their own missteps is not just an optimization—it’s a necessity.











