Object Recognition is a computer vision task that involves identifying the objects present in an image or a video frame. Object tracking, on the other hand, deals with identifying an object (or multiple objects) in a video stream and following its movement over time. These technologies are crucial for a wide array of applications, from autonomous driving and surveillance to robotics and augmented reality, allowing systems to perceive and interact dynamically with their environment.
Object Recognition
This involves identifying and categorizing objects present in an image or a video frame. The goal is to answer, “What is this object?”. Object recognition often involves:
- Localization: Determining the position of the object, usually by drawing a bounding box around it.
- Classification: Assigning a label (e.g., car, person, dog) to the detected object.
Object Tracking
This involves following an object (or multiple objects) over time in a sequence of frames (a video). The goal is to maintain the identity and location of the object as it moves. Object tracking typically builds upon object detection. Once an object is detected, a tracking algorithm attempts to follow it in subsequent frames.
Key Differences
- Scope: Object recognition is often performed on individual images or frames, while object tracking operates on sequences of frames.
- Output: Object recognition typically outputs bounding boxes and class labels for detected objects in a frame. Object tracking outputs the trajectory of objects over time, often assigning unique IDs to each tracked object.
Application
These technologies are fundamental to many applications, including:
- Autonomous Vehicles: Detecting and tracking pedestrians, vehicles, and traffic signs.
- Surveillance: Monitoring areas for specific objects or people, tracking their movements.
- Robotics: Enabling robots to perceive and interact with their environment.
- Human-Computer Interaction: Gesture recognition, gaze tracking.
- Sports Analytics: Tracking players and the ball in a game.
- Augmented Reality: Overlaying digital content onto real-world objects and having it move with the tracked object.

Evaluation of Object Detection Frameworks
To determine the optimal strategy for integrating robust object detection capabilities, we are conducting a comparative evaluation of leading frameworks. This analysis focuses on key solutions across both on-device and cloud-based paradigms, considering their respective strengths, target platforms, and operational models.
Google ML Kit Custom Dataset for Object Recognition (Google – On device)
Google ML Kit offers robust capabilities for detecting and tracking objects across consecutive video frames. When an image is processed by ML Kit for object detection, the system can identify up to five distinct objects within that image, simultaneously determining the precise position of each. ML Kit allows developers to use custom TensorFlow Lite models for object detection and tracking. This enables you to recognize objects specific to your use case that might not be covered by the pre-trained models.
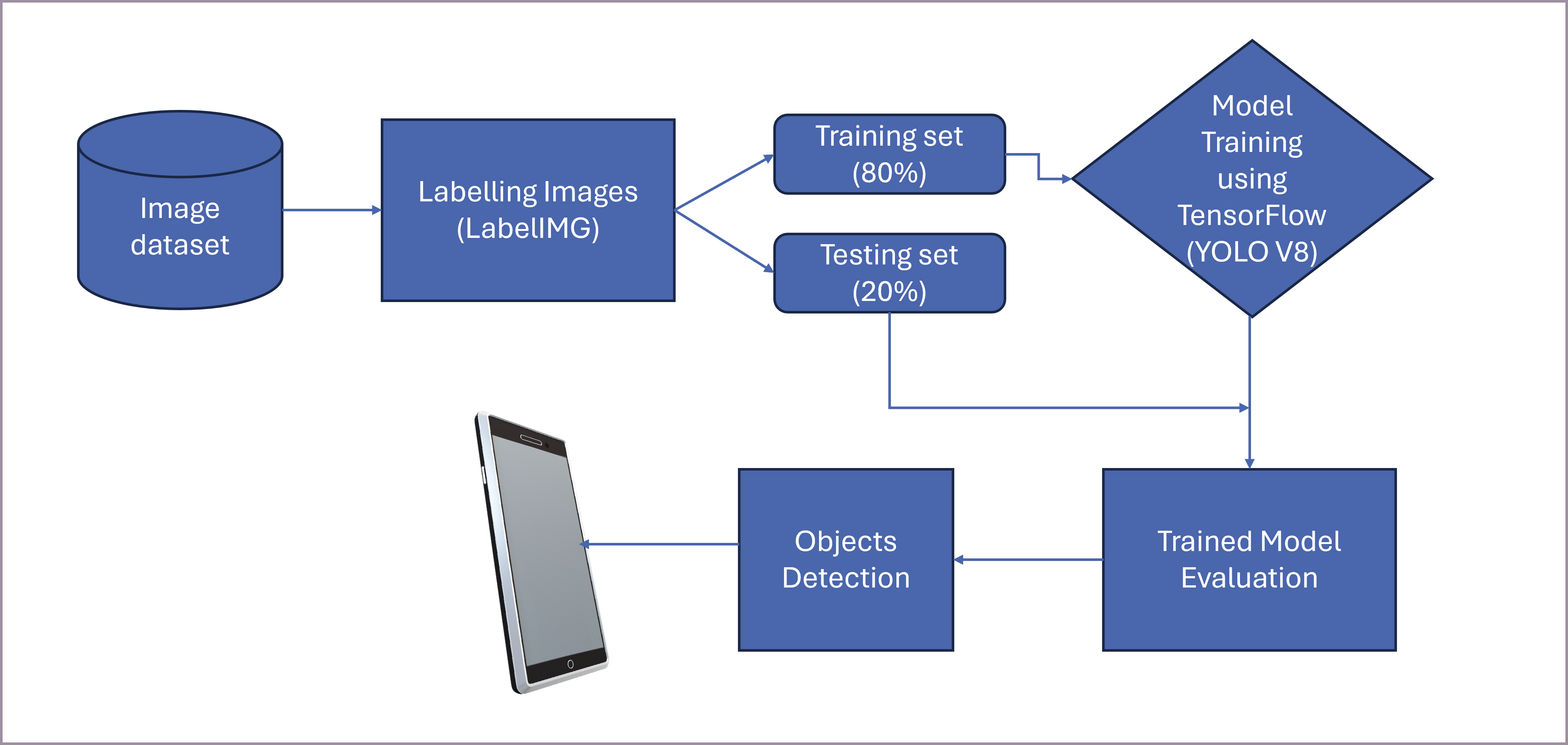
Using a Custom Dataset
To use a custom dataset with ML Kit, you need to follow these steps:
- Dataset Creation and Annotation: You need to create a dataset of images containing the objects you want to detect. Each object in the images must be labeled with a bounding box and a class name. Common annotation tools like Labelimg, Label Studio, or RectLable can be used for this purpose.
- Model Training: You then train an object detection model using this annotated dataset. You can use various frameworks for this, such as TensorFlow Lite Model Maker, TensorFlow, AutoML, or Vision Edge. These tools can output a TensorFlow Lite(.tflite) model, which is the format ML Kit uses.
- Model Integration: You integrate the .tflite model into your Android or iOS application using the ML Kit SDK.
- Inference: You use the ML Kit Object Detection and Tracking API, providing it with the input image, and it will use your custom model to detect and optionally track the specified objects.
Advantages of Custom Models in ML Kit
- Tailored Recognition: You can detect and classify objects specific to your needs.
- Improved Accuracy: Training on a domain-specific data set can lead to higher accuracy for specific objects compared to general-purpose models.
- On-device Processing: ML Kit runs the model directly on the device, offering speed and privacy benefits.
Disadvantages of Custom Models in ML Kit
- Data Requirement: Training a good custom model requires a significant amount of well-annotated data.
- Training Effort: You need to manage the model training process, which can be complex and computationally intensive.
- Model Size: Custom models can be larger than the default ML Kit models, potentially increasing the app size.
AWS Rekognition for Object Detection (Amazon Web Services – Cloud based)
Amazon Rekognition provides a cloud-based image and video analysis service. Its “Detect Labels” feature can identify objects, scenes, and concepts in images.
How it Works for Object Detection
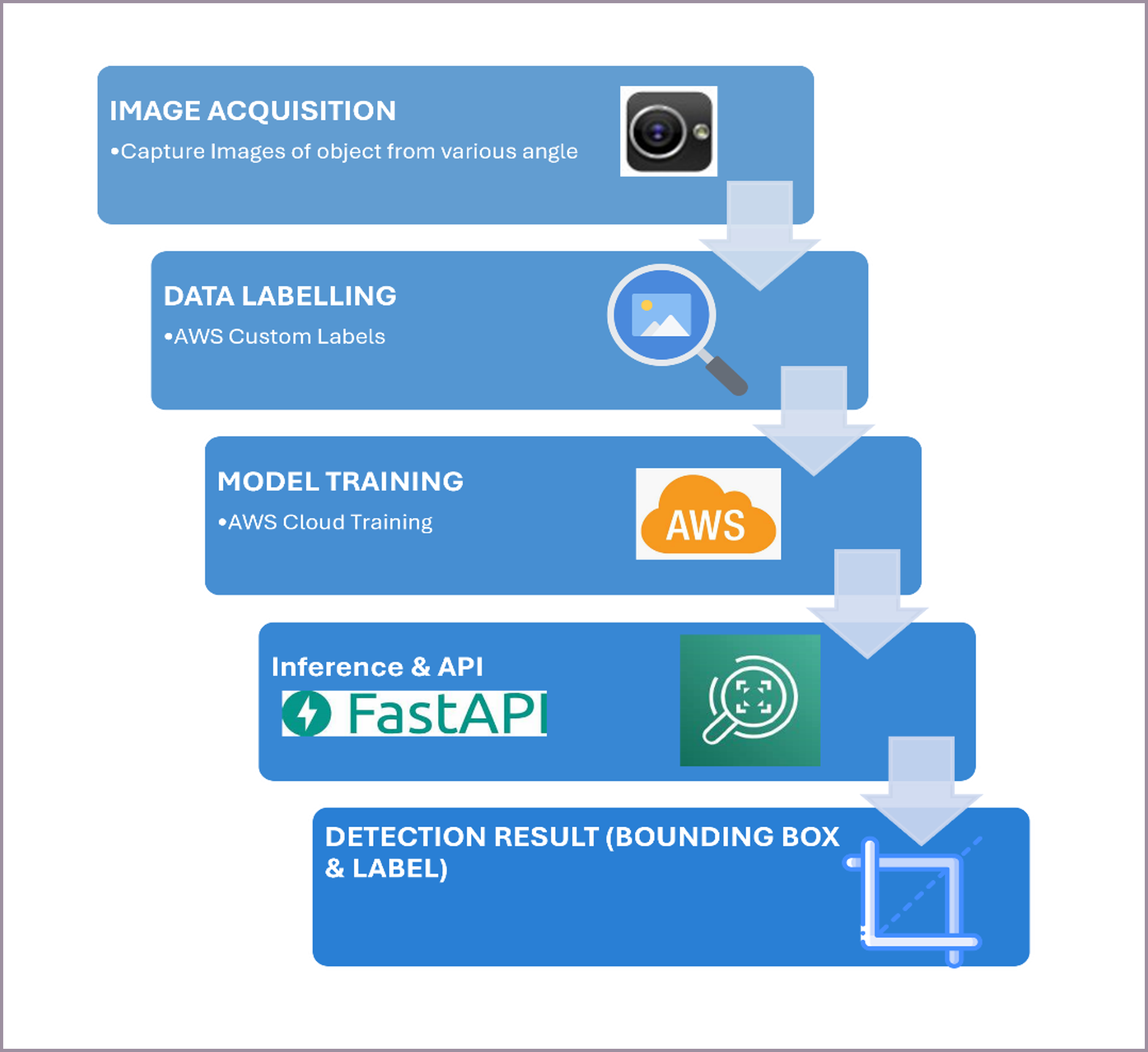
You can create a Proof of Concept (PoC) that showcases a streamlined object detection workflow. This PoC integrates a mobile application for image acquisition with a cloud-based processing backend.
The core functionality involves:
- Mobile Image Capture: Users capture images of objects directly from a mobile device.
- Secure Transmission to EC2: This image is then securely transmitted to a FastAPI application hosted on an AWS EC2 instance.
- AWS Rekognition Integration: The FastAPI backend invokes the AWS Rekognition service to perform advanced object detection on the received images.
- Bounding Box Return: Upon successful detection, the bounding box coordinates for the identified objects are returned from AWS Rekognition, processed by the FastAPI application, and then sent back to the mobile application for real-time visualization.
This PoC validates the technical feasibility and integration points for a robust object detection solution.
Advantages of AWS Rekognition
- Ease of Use: It is a managed service, so you do not need to worry about model training or infrastructure.
- Scalability: It can manage a large volume of image and video analysis.
- Pre-trained Models: It uses powerful pre-trained models that are continuously improved.
- Additional Features: Rekognition offers other features like face detection, text detection, and unsafe content detection.
Disadvantages of AWS Rekognition
- Cloud Dependency: Requires an internet connection to use the service.
- Cost: You are charged based on the number of images and videos processed.
- Limited Customization for Object Detection: While Rekognition Custom Labels allows training for image classification, its direct customization for object detection with bounding boxes is more focused on identifying custom objects rather than detailed spatial localization compared to training a model from scratch. However, the general “Detect Labels” feature does provide bounding boxes for many common objects.
Core ML for Object Detection (Apple – On device)
Apple’s machine learning framework, Core ML, enables the integration of trained machine learning models into Apple applications (iOS, macOS, watchOS, tvOS). You can use Core ML with the Vision framework to detect objects.
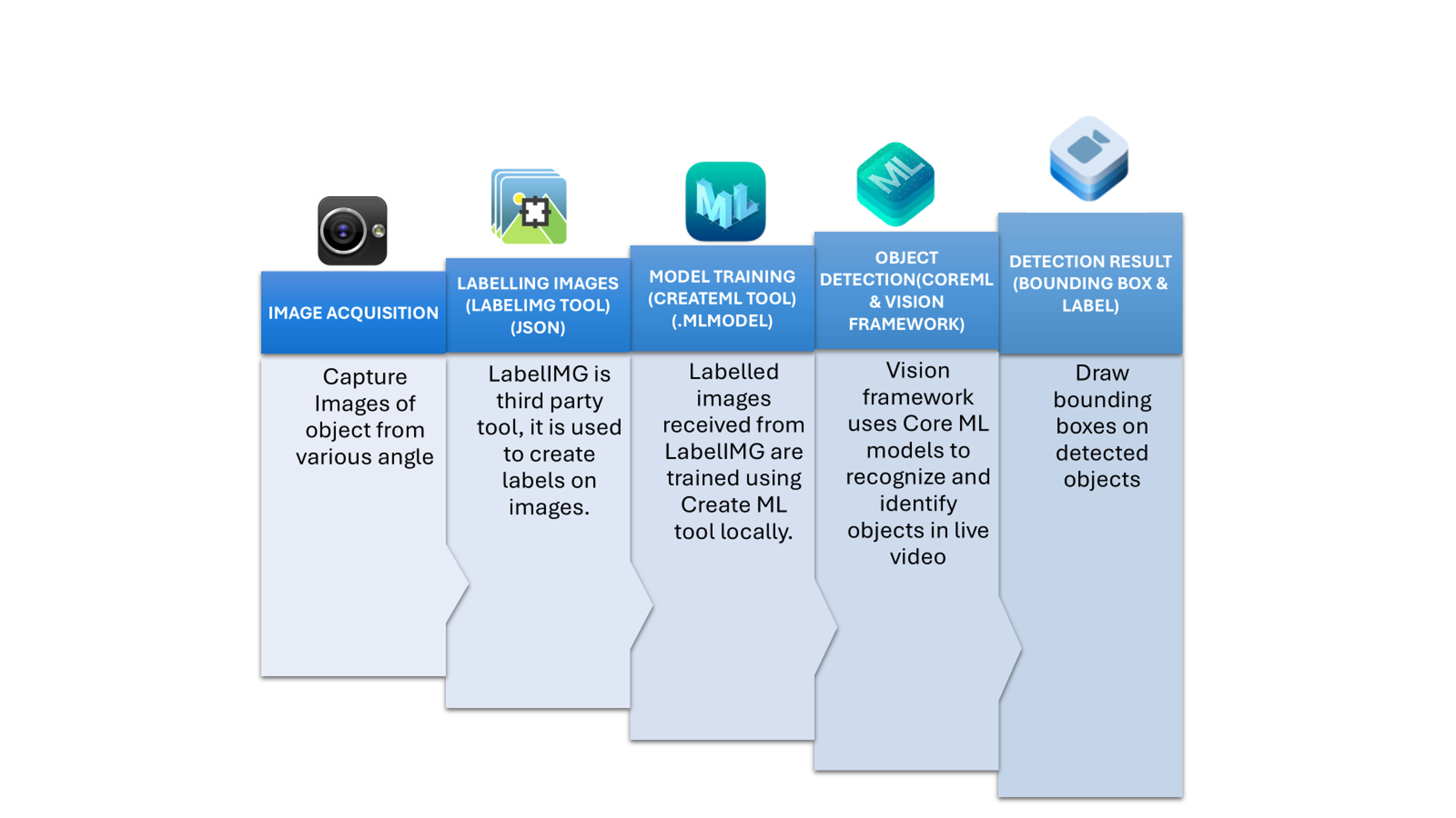
How it Works
- Model Creation: Collect a set of images with efficient size from different angles and diversity to reflect the data set you expect to predict. Create annotations/labels for each image, containing labels and bounding boxes for each labeled object to show what to detect in an image. Common annotation tools like Labelimg, Label Studio, or RectLable can be used for this purpose.
Train labeled images using CreateML tool or using Turi create. Apple’s framework and application for building and training machine learning models on your Mac. This generates models in (.mlmodel) format. - Model Conversion: You typically train an object detection model using a framework like TensorFlow, or PyTorch and then convert it to the Core ML model format (.mlmodel) using Core ML Tools.
- Vision Integration: In your app, you use the Vision framework along with your Core ML model. Vision provides high-level APIs to perform image analysis tasks, including object detection using a Core ML model. It manages image preprocessing and interpreting the model’s output.
- Output: The Vision framework returns observations of detected objects, including their bounding boxes and confidence scores.
Advantages of Core ML
- On-device Performance: Core ML is optimized to run efficiently on Apple devices, leveraging the CPU, GPU, and Neural Engine.
- Privacy: Processing happens locally on the device.
- Integration with Apple Ecosystem: Seamlessly integrates with other Apple frameworks like Vision and Create ML.
- Create ML: Apple provides the Create ML app, which allows you to train custom object detection models with a user-friendly interface, directly outputting Core ML models.
Disadvantages of Core ML
- Platform Lock-in: Core ML models primarily run on Apple devices.
- Conversion Required: Models trained in other frameworks need to be converted. While Core ML Tools is quite versatile, the conversion process might sometimes have limitations.
A Comparative Guide to Google ML Kit, Apple Core ML and AWS Rekognition
|
Feature/Aspect |
Google |
Apple |
AWS |
|
Primary |
Mobile app |
Native Apple |
Cloud-based |
|
Execution |
On-device |
On-device |
Cloud only |
|
Offline |
For on-device |
Yes |
No (requires |
|
Ease of |
High (With |
Moderate |
High (simple |
|
Custom |
Yes |
Yes (conversion |
Yes |
|
Real-time |
Excellent |
Excellent |
Can be near |
|
Privacy |
Excellent (on-device |
Excellent |
Lower (data |
|
Scalability |
Limited by |
Limited by |
Highly |
|
Cost |
Free for |
Free (part of |
Pay-as-you-go |
|
Integration |
Seamless with |
Deep |
Seamless with |
|
Advanced |
Object |
On-device |
Video |
|
Typical |
Mobile app |
iOS/macOS |
Backend |
In summary, each of these platforms offers different approaches and trade-offs for object recognition and tracking, depending on your specific needs regarding customization, deployment environment, cost, and ease of use.













Topic is very well explained.