Hallucinations in the context of Language Models refers to instances where the model response may seem credible but is factually incorrect or non sensical. We can understand this better with an example,
Let’s pose a simple question to a widely used language model:
“How many r’s are there in the word Strawberry?”

The correct answer is 3. However, the model initially responded with an incorrect answer: 2. When given negative feedback, it revised its response — but again incorrectly — this time stating there was only 1 “r.”
This example highlights a key limitation of large language models: even with seemingly simple factual questions, they can produce incorrect answers.
Why do LLM’s hallucinate?
To understand why LLM’s hallucinate, it is important to recognize that Language models aren’t search engines or databases to retrieve the right answer for a query. LLM’s are trained on vast amounts of text data sourced from books, the internet, etc. to learn patterns and relationships in the text.
So, when a user prompts the model with a query, the model doesn’t retrieve a factual answer in the traditional sense. Rather, it generates a response by predicting the next most likely words based on the patterns it has learned & not on logic or factual accuracy.
So, when we ask the LLM, “How many r’s are there in the word Strawberry?”, the model is not going to parse each letter in the word, instead it will generate a response that would seem contextually accurate.
More general causes of hallucinations can be,
· Incorrect, outdated or biased information provided during training
· No built-in fact-checking for model responses
· LLMs are trained to be helpful & would rather guess the answer to an unfamiliar question rather than responding with “I don’t know”
· High value for parameters like temperature that control randomness of response
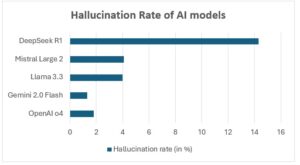
Among the popular language models in use today, DeepSeek R1 saw the highest rate of hallucinations among its peers at over 14% while OpenAI’s o4 model and Gemini 2.0 Flash recorded the lowest rates of hallucination
Reducing hallucinations in model response
A theoretical approach to reducing hallucinations in language models would be to retrain the model with clean, high-quality data. However, with the size and complexity of LLMs, this method is impractical. Instead, more feasible solutions focus on adjusting model parameters and how we interact with the model. We can broadly categorize methods of reducing hallucinations into prompt based & system-based approaches
* Prompt based methods
1. Chain of Verification prompting
In this technique, the model is not just asked to provide an answer but is also instructed to justify its response with the relevant fact-checks. This multi-step self-verification process reduces the chances of hallucinations.
An example of this can be “How many Rs are in ‘Strawberry’? First answer, then explain your reasoning, and finally check the result by parsing the letters individually”
Models like Claude Sonnet 3.7 & Deepseek R1 implement this
2. Self-Reflection Prompts
In this approach, we encourage the model to re-evaluate its response by engaging in a self-correction loop helping it to flag potential issues in its own output.
Ex: “You just provided an answer. Before finalizing it, re-read your response, check it for any logical inconsistencies or factual errors, and if unsure, provide a disclaimer or indicate areas that need further verification.”
3. Iterative Refinement Prompt
In this approach, we ask the model to iteratively refine its response each time asking it to justify & improve upon its previous output.
Ex: “Provide an initial answer. In your next response, refine it by addressing any areas you might have missed or where you feel less confident.”
This technique is implemented in Deepseek R1 model which when prompted, iteratively refines its response & even shows the reasoning for it
4. Role Assignment Prompting
This approach involves assigning the model with a specific identity or goal thereby shifting the model’s behavior to prioritize caution over fluency in its responses.
Ex: “You are a meticulous fact-checker. Respond only if you are 100% certain; otherwise say ‘I need to verify this”
* Model-Centric Approaches
1. Using Retrieval Augmented Generation (RAG)
One of the most effective ways to decrease hallucinations in LLM’s is to integrate an RAG with the LLM. RAGs generate and retrieve insights from domain specific datasets. The LLM can use these insights to generate a summary of information instead of generating responses from scratch
2. Post-Generation Fact-Checking Models
A fact-checking model or service can be used to verify the output before it is presented to the user. This when automated into the pipeline can flag and correct hallucinations.
3. Limiting Randomness
Using a lower temperature setting in the model’s generation process to limit randomness can reduce hallucinations. Hallucinations are more likely in high-temperature settings where the model explores more creative paths while providing a response.
4. Guardrails and Monitoring
Guardrails are predefined constraints or policies that restrict the model’s behavior in specific domains or scenarios. These can include hardcoded rules, filters for harmful content, or constraints that prevent speculative outputs. Continuous monitoring systems also help detect and correct hallucinations in real-time, especially in production environments.
5. Human-in-the-Loop
Incorporating human reviewers into the feedback loop allows for real-time quality control and intervention. This is particularly effective in high-stakes domains like healthcare, legal, or finance, where human expertise ensures factual accuracy and ethical alignment. HITL systems also generate valuable data for improving the model over time.
6. Responsible Data Quality & Training
Ensuring that the model is trained on clean, verified, and representative datasets significantly reduces hallucinations. This includes filtering out misinformation, removing low-quality text, and minimizing duplication or inconsistencies. Domain-specific fine-tuning also helps improve factual grounding in specialized areas.
7. Bias Detection and Mitigation
Hallucinations are often amplified by underlying biases in the training data. Proactively identifying and mitigating these biases—whether cultural, political, or linguistic will help prevent distorted or incorrect outputs. Techniques like adversarial training and fairness-focused evaluation are commonly used in this context.
8. Improved Evaluation Metrics
Traditional benchmarks may not fully capture the subtle ways hallucinations appear. Newer metrics, such as Faithfulness, Groundedness, and Factual Consistency, offer a more nuanced way to assess model outputs. Continuous evaluation using real-world prompts and user feedback is key to identifying and addressing hallucination risks.
How Language Models are learning to mitigate hallucinations
Developers and researchers behind leading language models are actively working on finding solutions to address the challenge of hallucinations.
- OpenAI, the company developing ChatGPT is prioritizing more reliable resources to improve quality of training in data. Newer versions of ChatGPT have been trained to respond with “I don’t know” in case the model isn’t sure the response is accurate. The newer versions of the model also include web browsing allowing the model to respond with real data instead of guessing.
- Anthropic AI’s Claude Sonnet utilizes constitutional AI techniques, which involve training models to follow a set of principles that guide its behavior. The model also employs reinforcement learning with Human Feedback where correct responses are rewarded and incorrect ones are penalized. Claude also declines to provide speculative information for topics outside its knowledge base.
- DeepSeek is employing enhanced training techniques to address the significantly higher rates of hallucination in its R1 model, including domain specific fine-tuning & integrating its models with external knowledge bases to verify its responses in real time
Looking Forward
Language models have come a long way since they first entered the mainstream, but they are still far from perfect. With significant research happening in this area, models now show much lower rates of hallucination, and the future of more reliable models looks promising, even if we may not be able to eliminate hallucinations entirely.
But as strange as it may sound, hallucinations aren’t always as bad as they seem. They can be an essential feature, that enables models to be creative. If we want AI to “think outside the box,” it’s crucial for them to occasionally venture beyond their training data. This ability to generate new stories, provide fresh ideas, and brainstorm innovative solutions is what has made LLMs so effective and popular.








