Cybersecurity demands more than reactive defences—it calls for proactive, intelligent systems that can adapt and improve with every interaction. In our earlier blog, Learning on the Fly: User-Driven Adaptation in Small Language Models, we explored how Small Language Models (SLMs) can be fine-tuned to incorporate user feedback, transforming them from static utilities into dynamic, evolving assets for cyber defense.
That work focused on capturing user dissatisfaction signals and feeding them back into SLMs to create a self-learning loop. Building on that foundation, this blog shifts the focus to an agentic AI use case—where models don’t just generate answers but must decide which external tool to use for a given problem.
The challenge is clear: what happens when an agent picks the wrong tool? Imagine a security analyst asking, “Is this IP malicious?”, but the agent mistakenly chooses a GeoIP Lookup instead of a reputation check. Such errors not only erode user trust but also reduce the system’s operational effectiveness. However, if these decisions are systematically logged, analyzed, and fed back into the learning process, agents can become more accurate over time.
In this blog, we explore how to log tool-selection correctness in agentic AI systems. By tracking when an agent chooses the right tool versus when it does not, and by applying lightweight rules to determine ground truth, organizations can build feedback loops that extend beyond text outputs—laying the groundwork for self-improving, tool-aware AI agents in cybersecurity and beyond.
Why This Matters
SLMs are efficient, cost-effective, and well-suited for enterprise deployment, but a 1B parameter SML is not inherently intelligent enough to orchestrate tools reliably. By continuously feeding it validated tool decisions, we enable the model to gain expertise in specific operational contexts.
This approach effectively transforms the SML into a domain-specific expert system, much like a Mixture of Experts (MoE), but optimized for enterprise scenarios where resource efficiency and auditability are critical.
The full demonstration of this pipeline, along with reference code, is available in the public GitHub repository: https://github.com/ameya/agentic-slm-demo.
Cybersecurity Application
Consider a scenario where a SOC agent supports analysts by choosing the right tool for investigating suspicious IP addresses:
- “Where is this IP located?” → correct choice: GeoIP Lookup
- “Who owns this IP address?” → correct choice: WHOIS Lookup
- “Is this IP malicious?” → correct choice: Reputation Check
Yet, agentic systems don’t always get this right. An agent might mistakenly use a GeoIP lookup when asked about maliciousness—producing an answer that sounds valid but misses the analyst’s real intent.
To address this, we can log each interaction in a structured table containing:
- The input prompt,
- The tool selected by the SLM,
- The expected tool (derived through rules or validation by a stronger LLM),
- A correctness label (true/false).
Once collected, these logs serve two purposes:
- Performance tracking — enabling metrics like accuracy, error trends, and confusion matrices of tool choices.
- Training data generation — correctness labels provide ground truth that can be used to fine-tune the SLM, so it learns to avoid repeating the same mistakes.
This approach transforms tool-choice errors into learning opportunities. While our example highlights cybersecurity tasks, the same method applies broadly to domains such as finance, healthcare, or customer service—anywhere agentic AI must pick the right tool to deliver the right outcome.
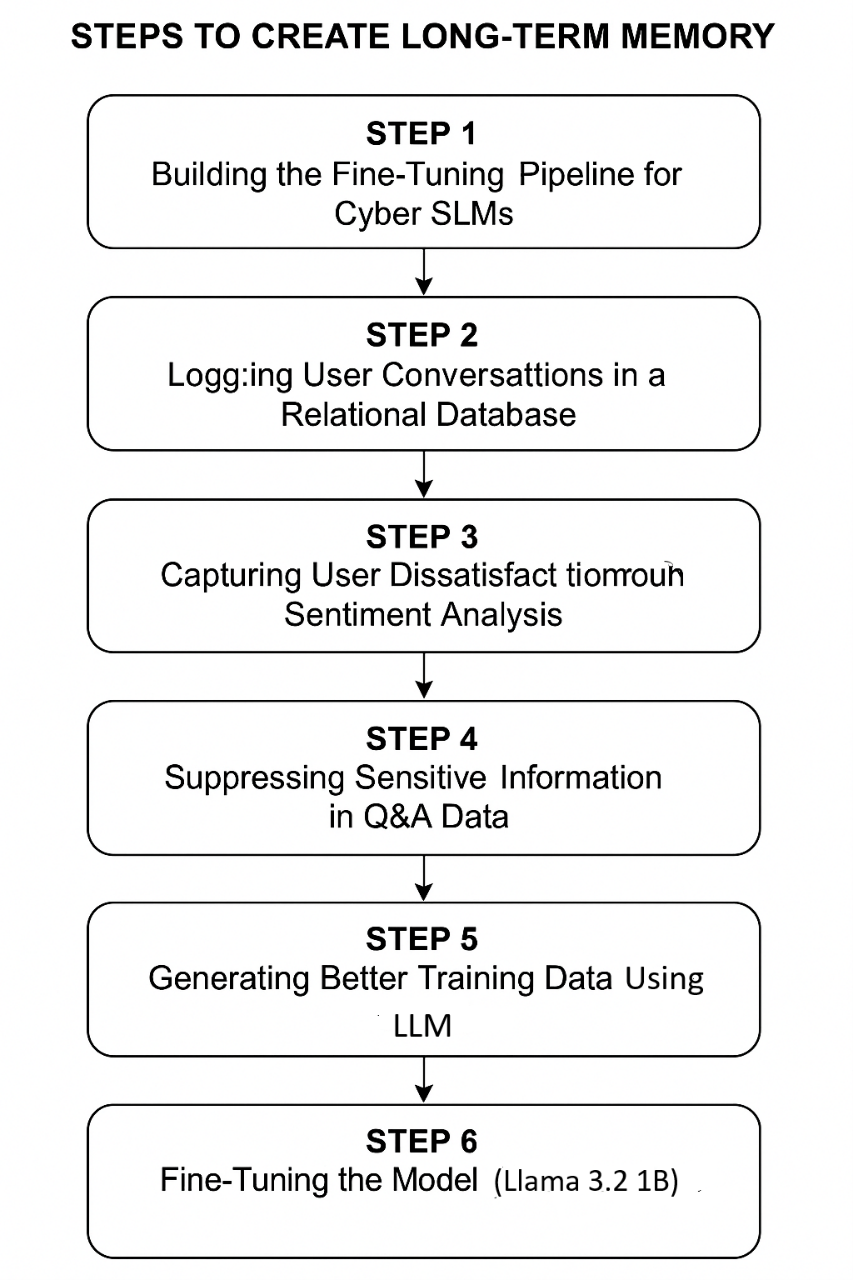
Steps to Create Long-Term Memory for Agentic SLM
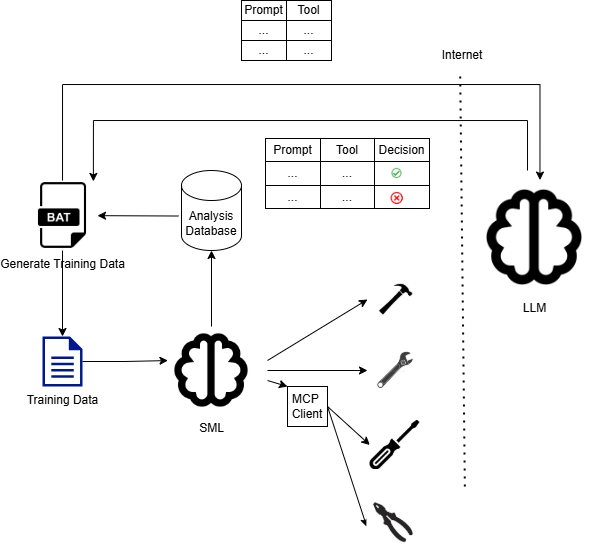
Step 1: Building the Fine-Tuning Pipeline for Agentic SLMs
To enable a Small Language Model (SLM) to improve its tool selection intelligence, we need a modular, auditable, and secure fine-tuning pipeline. The goal is to create a loop where model performance improves based on logged tool decisions—particularly where the agent picked the wrong tool.
Key Components of the Pipeline:
- Prompt & Tool Capture: Each user prompt and the tool chosen by the agent is logged.
- Decision Validation: Analysts or automated heuristics mark whether the tool selection was correct (✅) or incorrect (❌).
- Analysis Database: A structured store that keeps a record of prompts, tools, and decision outcomes.
- Batch Processing (BAT): A Python application that periodically extracts logs, prepares training datasets, and pushes them for further analysis.
- Augmented Data Generation: A large external LLM enriches the dataset by generating synthetic training examples, especially for error cases.
- Fine-Tuning the SML: Using LoRA/QLoRA or PEFT adapters to make the 1B-parameter SML more intelligent without heavy compute costs.
- Benchmark & Feedback Loop: Each fine-tuned SML is tested against baseline performance and redeployed, closing the loop.
Step 2: Logging Agentic Tool Interactions in a Relational Database
Capturing real-world tool selection decisions is the foundation of a self-learning Agentic system. Instead of logging raw session histories or user identifiers, the focus is on prompts, tool metadata, and correctness flags.
Minimalist Schema:
| Column | Type | Description |
|---|---|---|
| id | INT | Unique identifier for the interaction |
| prompt | TEXT | User’s input query |
| tool_name | TEXT | Name of the selected tool |
| tool_desc | TEXT | Metadata/description of the tool |
| decision | BOOL | Correct (1) / Incorrect (0) selection |
Example Interaction:
- Prompt: “Correlate login failures across AD logs.”
- Tool Chosen: LogCorrelator
- Tool Description: Cross-checks failed logins across domains
- Decision: ❌ (wrong tool — should have been AD-Audit)
This schema ensures we can systematically analyze failure cases without exposing sensitive organizational data.
Step 3: Identifying Wrong Tool Decisions
Not every interaction indicates a problem—but when the agent selects the wrong tool, it’s a critical signal for retraining. By analyzing decision logs, we can detect common failure patterns such as:
- Confusion: The SML maps a prompt to a tool with similar keywords but wrong functionality.
- Over-generalization: The same tool is chosen for too many unrelated tasks.
- Gaps in training data: The SML hasn’t seen enough examples for niche tools.
These patterns provide the foundation for generating better training data.
Step 4: Suppressing Sensitive Metadata
Before preparing datasets, the pipeline must remove or anonymize sensitive organizational metadata. For example:
- Tool names that reveal internal projects.
- Paths or commands embedded in tool descriptions.
- Proprietary log sources or datasets
A lightweight PII scrubber can be applied here, similar to cybersecurity chat scenarios, ensuring compliance with GDPR and enterprise data safety.
Step 5: Generating Better Training Data Using an External LLM
Once raw logs are cleaned, a large external LLM (e.g., GPT-4) generates better training data:
- Improves the mapping of prompts → correct tools.
- Suggests synthetic variations of prompts that could confuse the SML.
- Expands coverage for rarely used tools.
Sample Prompt for GPT-4 Augmentation:
“You are assisting in training an Agentic SOC assistant. Below is a prompt and the incorrect tool chosen. Suggest the correct tool, and generate 2–3 alternate prompt–tool pairs that should be added to improve training coverage.”
Step 6: Fine-Tuning the SML
With curated training data, the SLM (1B parameter) is fine-tuned using parameter-efficient techniques:
- Base Model: Custom enterprise SLM (1B)
- Technique: LoRA / QLoRA / PEFT
- Goal: Improve tool orchestration accuracy while keeping compute costs minimal
This allows the smaller SLM to evolve into a specialized decision-making expert—a lightweight but intelligent Mixture of Experts (MoE).
Step 7: Testing and Benchmarking the Fine-Tuned Agentic Model
Fine-tuning only matters if it improves real-world tool selection. Benchmarking involves:
• Correctness: % of times the right tool is chosen
• Efficiency: Reduction in unnecessary tool calls
• Coverage: Ability to handle rare or unseen tools
• Analyst Feedback: Validation from SOC analysts in real workflows
Sample Test Cases:
• Prompt: “Parse suspicious PowerShell commands.” → Expected Tool: ScriptAnalyzer
• Prompt: “Detect Kerberos ticket anomalies.” → Expected Tool: AD-Audit
• Prompt: “Summarize last 24 hours of IDS alerts.” → Expected Tool: AlertSummarizer
Over time, repeated cycles of logging, cleaning, and retraining help the SML mature into a trustworthy agentic expert in enterprise environments.
Agentic Context Engineering: Evolving the Agent’s Memory and Strategy
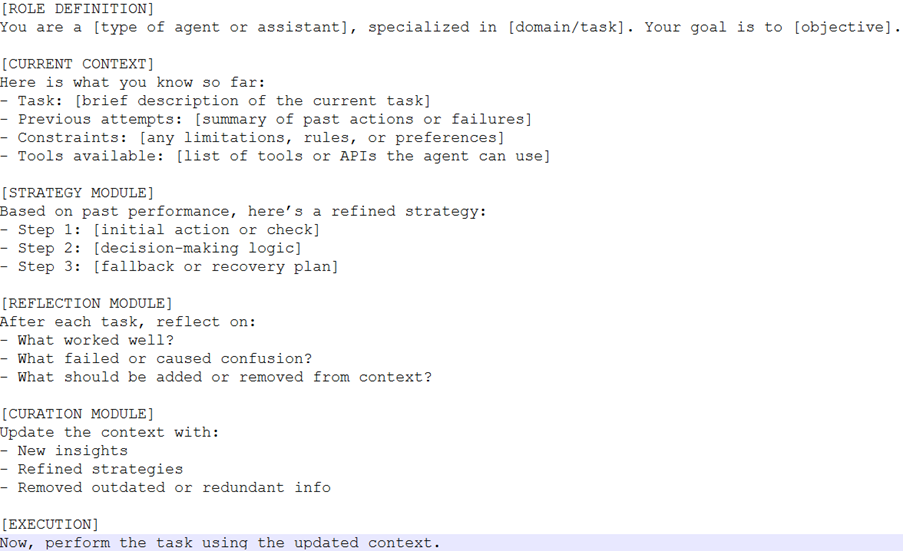
While fine-tuning improves the model’s tool selection accuracy, Agentic Context Engineering (ACE) ensures that the agent evolves its decision-making playbook over time—without retraining. This involves dynamically updating the agent’s context with:
- Successful strategies from past interactions
- Failure cases and their corrected outcomes
- Domain-specific heuristics and tool usage patterns
Instead of relying solely on static prompts or retrained weights, ACE treats context as a living memory—a structured, modular, and editable layer that guides the agent’s behavior.
Prompt Template for Agentic Context Engineering
Cybersecurity Example: Hallucination vs. Context-Engineered Response
Without Proper Context (Hallucination)
Prompt:
“Is this IP address malicious?”
Agent Response:
“GeoIP Lookup Result: The IP is located in Frankfurt, Germany.”
Issue:
The agent incorrectly assumes location implies maliciousness. It selects the wrong tool (GeoIP) and gives a misleading answer.
With Agentic Context Engineering
Updated Context:
- Task: Identify malicious IPs
- Previous failure: GeoIP used instead of Reputation Check
- Correct tool: ThreatIntelReputation
- Strategy: Always use reputation-based tools for maliciousness queries
Prompt:
“Is this IP address malicious?”
Agent Response:
“ThreatIntelReputation Result: The IP has been flagged in 3 threat feeds for malware distribution. Risk Score: High.”
Outcome:
The agent selects the correct tool and provides a relevant, actionable response—thanks to context engineering.
Conclusion
As enterprises move toward Agentic AI systems, the ability to learn from past actions becomes as important as generating new responses. By systematically logging tool choices, validating correctness, and feeding that data back into a fine-tuning loop, we give Small Language Models (SLMs) the ability to evolve into specialized experts.
This approach transforms a lightweight 1B SLM from a generic assistant into a domain-aware Mixture of Experts (MoE), capable of making smarter, context-driven decisions. Unlike static models, the agent grows with every interaction—adapting not only to user prompts but also to the operational tools of the enterprise.
In doing so, we bridge the gap between efficiency and intelligence: large LLMs provide synthetic data generation and reasoning depth, while fine-tuned SLMs deliver cost-effective, reliable decision-making at scale. Over time, this creates a self-learning, auditable, and trustworthy AI layer that enterprises can safely embed into their SOCs and business workflows.
Complementing this, Agentic Context Engineering (ACE) introduces a dynamic memory layer that evolves with each interaction. ACE reduces hallucinations and improves decision-making by treating context as a modular, editable playbook—updated through generation, reflection, and curation. This enables agents to adapt without retraining, making them more resilient, accurate, and aligned with domain-specific goals.











