Fine-tuning small language models (SLMs) is an increasingly popular way to adapt compact AI systems to specific tasks, especially when resources are limited. But how much effort is needed to teach a small model just 5–6 simple facts? We compared full fine-tuning with several parameter-efficient tuning (PEFT) methods—LoRA, QLoRA, and IA³—to evaluate their effectiveness on this minimal task. Full fine-tuning enabled the SLMs to learn quickly and accurately, but it came at a high computational cost. LoRA emerged as a well-balanced option, achieving strong performance with less overhead. QLoRA saved memory but required longer runtimes. Surprisingly, IA³ performed poorly, offering little factual learning despite its efficiency. These results suggest that even for small models and simple tasks, fine-tuning strategies vary widely in effectiveness, highlighting the importance of selecting the right method based on practical constraints.
What is Full Fine-Tuning?
Full fine-tuning is a method where all the parameters of a pre-trained language model are updated during training on a new, task-specific dataset [1].
What Is PEFT (Parameter-Efficient Fine-Tuning)?
Instead of updating the entire model during training, PEFT techniques adjust only a small portion—typically a few percent—of the model parameters. This targeted tuning approach offers several advantages [2, 3]:
- Lower memory usage
- Faster training
- Reusable base models
- Viable on consumer-grade hardware
Let’s briefly explore the two key PEFT techniques in focus for this study:
LoRA (Low-Rank Adaptation)
LoRA introduces low-rank matrices into specific weight layers (typically attention projections). During fine-tuning, only these matrices are updated while the base model remains frozen. The idea is that the weight update can be decomposed into two smaller matrices, drastically reducing the number of trainable parameters [4, 5, 6].
QLoRA
QLoRA builds on LoRA by combining it with 4-bit quantization of the base model weights, further minimizing memory usage. It enables training large models on a single GPU while maintaining performance, making it ideal for low-cost deployment [7].
IA³ (Infused Adapter by Attention Adjustment)
Modifies the attention mechanism by injecting learned scaling vectors without introducing large parameter matrices, resulting in minimal overhead [8].
Experimental Setup
Model Used
We used the LLaMA-3.2-1B model, a compact and efficient SLM, to test how well small models can learn and retain a few factual statements using various fine-tuning strategies.
Methods Evaluated
We explored different conditions as follows:
- Full Fine-Tuning with different epochs
- LoRA with rank (r) = 4 and alpha = 16
- LoRA with rank (r) = 8 and alpha = 32
- QLoRA with rank (r) = 8 and alpha = 32
- IA3 (with default configuration)
Metrics
The metrics below are used to evaluate the performance of different conditions.
- Training Runtime
- Training Loss
- Evaluation Accuracy (Cosine Similarity)
Dataset
A synthetic dataset comprising biography-style facts (e.g., education, work history of an individual).
Results
This section presents the experimental findings across five fine-tuning strategies: full fine-tuning, LoRA (r=4), LoRA (r=8), QLoRA (r=8), and IA³. The models were evaluated using three key metrics: evaluation accuracy, training loss, and training run time.
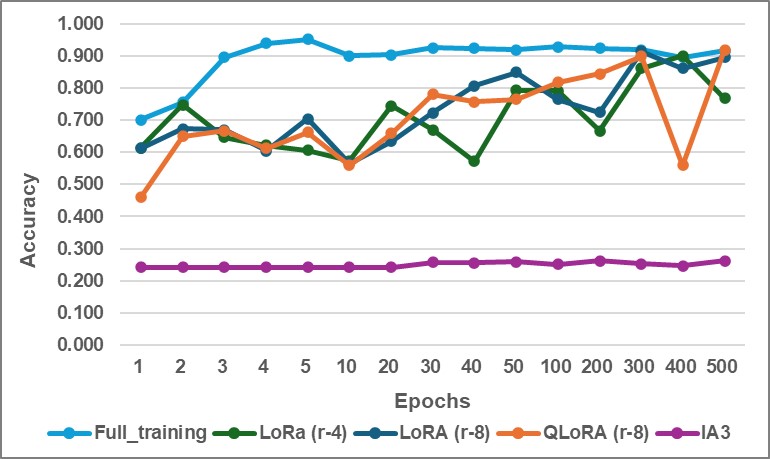
Figure 1: Evaluation Accuracy Comparison: Full training, LoRA (r=4), LoRA (r=8), QLoRA (r=8), and IA3.
As shown in figure 1, full fine-tuning demonstrates the fastest and highest convergence, reaching over 90% accuracy within just three epochs. Both LoRA configurations gradually improve, stabilizing below the full fine-tuning baseline after approximately 300 epochs, with LoRA (r=8) slightly outperforming LoRA (r=4). QLoRA (r=8) achieves similar accuracy trends to LoRA but with slower progress due to quantization-related overhead.
In contrast, IA³ shows the weakest performance, with evaluation accuracy fluctuating between 0.2 and 0.3 throughout the entire training period. It fails to demonstrate meaningful improvement, indicating a limited ability to internalize and retain factual knowledge in this task.
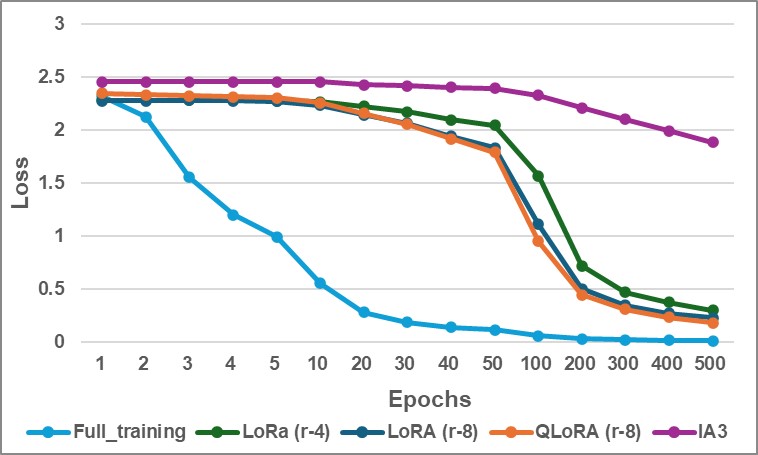
Figure 2: Training Loss Comparison: Full training, LoRA (r=4), LoRA (r=8), QLoRA (r=8), and IA3.
In Figure 2, Full fine-tuning again shows dominant performance, with the training loss dropping steeply and plateauing near zero in the first 100 epochs. LoRA and QLoRA demonstrate slower convergence: LoRA (r=8) achieves the closest loss reduction to full fine-tuning, followed by LoRA (r=4) in 500 epochs, while QLoRA converges more slowly due to quantization.
IA³ exhibits only a modest reduction in training loss, from approximately 2.5 to just under 2.0. This shallow decline reinforces the model’s limited learning capacity in this setup and correlates with its poor accuracy outcomes.
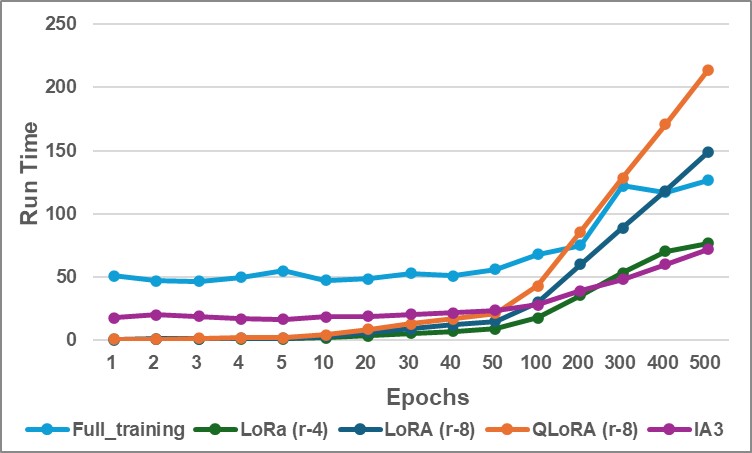
Figure 3: Training Runtime Comparison: Full training, LoRA (r=4), LoRA (r=8), QLoRA (r=8), and IA3.
Figure 3 shows that full fine-tuning requires more runtime even in the early epochs, but converges quickly to the best accuracy. Although this makes it efficient in terms of convergence speed, it remains less suitable for memory-constrained environments. LoRA (r=4) is the most efficient overall, maintaining consistently low runtime throughout training, while LoRA (r=8) incurs a slightly higher cost due to its increased rank.
QLoRA (r=8), while designed for memory efficiency, exhibits increased runtime after the 10th epoch, likely due to the computational overhead of handling quantized weights.
IA³ initially incurs a higher training cost than all PEFT methods, particularly within the first 50 epochs. However, its runtime plateaus and becomes more efficient over time, ultimately outperforming full fine-tuning in cost but still lagging behind LoRA in overall speed.
Discussion
The results highlight distinct trade-offs between training efficiency, memory usage, and performance across fine-tuning strategies, especially when comparing small and large language models:
- Full Fine-Tuning proves to be the most effective approach for small language models (SLMs). It delivers the highest accuracy and fastest convergence, with smaller models mitigating the typically high computational cost. However, full fine-tuning can increase the risk of catastrophic forgetting, where previously learned information may be lost during the training process. Despite this, it remains a practical and powerful choice when working with SLMs on tasks requiring precision and factual memorization.
- LoRA emerges as a strong candidate for large language models (LLMs). It significantly reduces training overhead while maintaining strong performance. LoRA with lower ranks (e.g., r=4) offers better runtime efficiency, while higher ranks (e.g., r=8) slightly improve accuracy at a reasonable cost—making it a scalable and general-purpose option for fine-tuning LLMs.
- QLoRA is best suited for scenarios where memory constraints outweigh concerns about training speed. While it enables fine-tuning on low-end GPUs through quantization, the increased runtime makes it less favorable when latency or iteration speed matters.
- IA³, despite its lightweight design and theoretical efficiency, underperforms across metrics. Its weak learning dynamics and limited factual retention suggest it is unsuitable for tasks requiring high accuracy or deep memorization. However, its simplicity may still offer value for minimal, low-stakes adaptations.
Future Work
Our experiments show that while full fine-tuning converges quickly to high performance—achieving strong accuracy within just a few epochs—both LoRA and QLoRA require significantly longer training to reach comparable results. This slower convergence presents a practical challenge for efficient model adaptation. Additionally, full fine-tuning carries a higher risk of catastrophic forgetting, where the model may lose previously learned knowledge during rapid updates [14].
Future work will focus on accelerating the early convergence of PEFT methods like LoRA and QLoRA. Potential directions include exploring adaptive learning rates, hybrid fine-tuning strategies, and improved initialization techniques to combine the efficiency benefits of PEFT with faster training dynamics. The goal is to narrow the gap in convergence speed without sacrificing the computational and memory advantages that make PEFT so appealing, while also addressing issues like catastrophic forgetting.
References:
- Lv, K., Yang, Y., Liu, T., Gao, Q., Guo, Q. and Qiu, X., 2023. Full parameter fine-tuning for large language models with limited resources. arXiv preprint arXiv:2306.09782.
- Ding, Ning, Yujia Qin, Guang Yang, Fuchao Wei, Zonghan Yang, Yusheng Su, Shengding Hu et al. “Parameter-efficient fine-tuning of large-scale pre-trained language models.” Nature Machine Intelligence 5, no. 3 (2023): 220-235.
- Adapter in Hugging face: https://huggingface.co/docs/peft/en/conceptual_guides/adapter.
- Yue Gang, Jianhong Shun, Mu Qing. Smarter Fine-Tuning: How LoRA Enhances Large Language Models. 2025. ⟨hal-04983079⟩
- Hu, Edward J., Yelong Shen, Phillip Wallis, Zeyuan Allen-Zhu, Yuanzhi Li, Shean Wang, Lu Wang, and Weizhu Chen. “Lora: Low-rank adaptation of large language models.” ICLR 1, no. 2 (2022): 3.
- Hugging Face: https://huggingface.co/docs/peft/en/package_reference/lora.
- Dettmers, Tim, Artidoro Pagnoni, Ari Holtzman, and Luke Zettlemoyer. “Qlora: Efficient finetuning of quantized llms.” Advances in neural information processing systems 36 (2023): 10088-10115.
- Liu, H., Tam, D., Muqeeth, M., Mohta, J., Huang, T., Bansal, M. and Raffel, C.A., 2022. Few-shot parameter-efficient fine-tuning is better and cheaper than in-context learning. Advances in Neural Information Processing Systems, 35, pp.1950-1965.
- S. Hayou, N. Ghosh, and B. Yu. The impact of initialization on lora finetuning dynamics. arXiv preprint arXiv:2406.08447, 2024.
- Mao, Y., Ge, Y., Fan, Y., Xu, W., Mi, Y., Hu, Z. and Gao, Y., 2025. A survey on lora of large Language Models. Frontiers of Computer Science, 19(7), p.197605.
- Zhao, J., Wang, T., Abid, W., Angus, G., Garg, A., Kinnison, J., Sherstinsky, A., Molino, P., Addair, T. and Rishi, D., 2024. Lora land: 310 fine-tuned llms that rival gpt-4, a technical report. arXiv preprint arXiv:2405.00732.
- Google Colab: https://colab.research.google.com/github/DanielWarfield1/MLWritingAndResearch/blob/main/LoRA.ipynb.
- Predibase: https://predibase.com/lora-land.
- Ding, M., Xu, J. and Ji, K., 2024. Why Fine-Tuning Struggles with Forgetting in Machine Unlearning? Theoretical Insights and a Remedial Approach. arXiv preprint arXiv:2410.03833.









