Key Use Cases Solved
Loss Prevention & Theft Detection
Our Video AI Agent effectively handles several loss prevention challenges without the need for fine-tuning by detecting:
-
Suspicious Activity & Security Threats with real-time analytics:
Retail theft and fraud cost businesses billions annually. NVIDIA VSS proactively adds safety measures to retailers by:
- Classifying with contextual understanding anomalous activity and loitering.
- Sending real-time alerts to security teams when suspicious activity is detected.
-
Product Damage, Spills, & Safety Hazards:
Ensuring customer and employee safety is vital. NVIDIA VSS helps retailers by:
-
- Detecting when products fall, are dropped, or sustain damage.
- Identifying liquid spills, debris, and slip hazards in high-traffic areas.
- Logging instances of negligence by staff or customers that lead to unsafe conditions.
- Triggering automatic alerts for clean-up crews and safety teams.
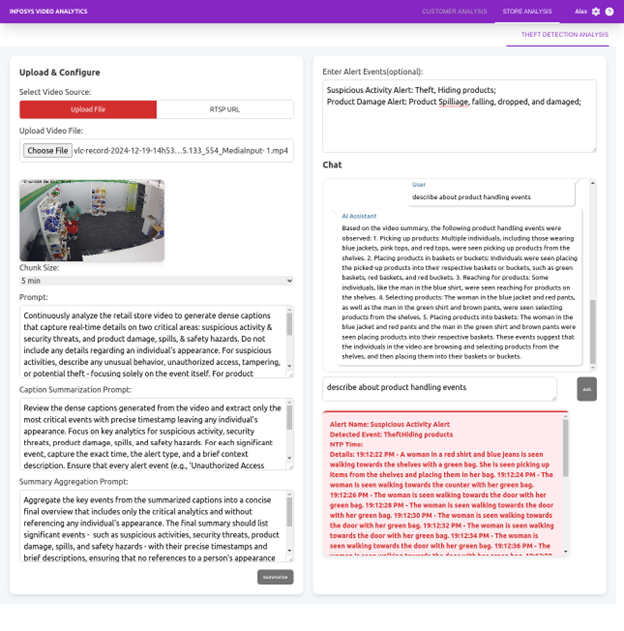
Prompt & Chunking Configuration
When a video is uploaded to the Video AI Agent, the system calls the summarize endpoint to generate a summary. The AI Blueprint handles the heavy lifting while allowing you to configure:
-
VLM Dense Captioning Prompt:
Controls the objects, events, and actions to capture.
Analyze retail store videos continuously to generate detailed captions that capture real-time details on two critical areas: suspicious activity & security threats, and product damage, spills, & safety hazards. Do not include any details regarding an individual’s appearance. For suspicious activities, describe any unusual behavior, unauthorized access, tampering, or potential theft – focusing solely on the event itself. For product damage and safety hazards, report instances of product breakage, spills, or unsafe conditions without mentioning personal details. Include precise timestamps or video time for every detection event and update the status dynamically as the video progresses. Format the output so that each event is clearly described with its context, exact time, and alert status for efficient analysis and summarization.
-
Caption Summarization (LLM) Prompt:
Combines dense captions into a coherent summary with the desired level of detail.
Review the dense captions generated from the video and extract only the most critical events with precise timestamp leaving any individual’s appearance. Focus on key analytics for suspicious activity, security threats, product damage, spills, and safety hazards. For each significant event, capture the exact time, the alert type, and a brief context description. Ensure that every alert event (e.g., ‘Unauthorized Access Event’, ‘Potential Theft Event’, ‘Spill Detection Event’) is clearly documented with its occurrence time and do not include individual’s appearance in alert details or description, so that only the most important analytics are included. The alerts generated must not contain any individual’s appearance details.
-
Summary Aggregation (LLM) Prompt:
Defines the output format, length, and key information for the final summary.
Aggregate the key events from the summarized captions into a concise final overview that includes only the critical analytics and without referencing any individual’s appearance. The final summary should list significant events – such as suspicious activities, security threats, product damage, spills, and safety hazards – with their precise timestamps and brief descriptions, ensuring that no references to a person’s appearance are included. Format the output for efficient summarization and analysis. Highlight critical events as alerts for alert generation. The alerts generated must not contain any individual’s appearance details.
-
Video Chunking Strategy:
Specifies chunk size and overlapping parameters for files or live streams.
Chunk Size= 5 min
Results & Observations
Our Video AI Agent was evaluated in a zero-shot setting to address key loss prevention challenges. Without any fine-tuning, the system leverages pre-defined prompts for dense captioning, summarization, and aggregation to detect activity, product damage, and customer behavior.
Key Observations
- Zero-Shot Efficacy: Without fine-tuning, the pre-trained VILA model successfully detected multiple loss prevention scenarios.
- Prompt & Chunking Configuration: Utilizing the VLM Dense Captioning, Caption Summarization, and Summary Aggregation prompts, along with a robust video chunking strategy, the agent generates coherent summaries and actionable alerts without task-specific training.
- Strengths & Limitations:
- Strengths: Reliable detection of high-level security threats and safety hazards; ability to generate timely alerts that assist in rapid response.
- Limitations: Occasional misinterpretation of subtle contextual cues may result in false positives or minor delays in alerting, indicating potential areas for improvement through fine-tuning.
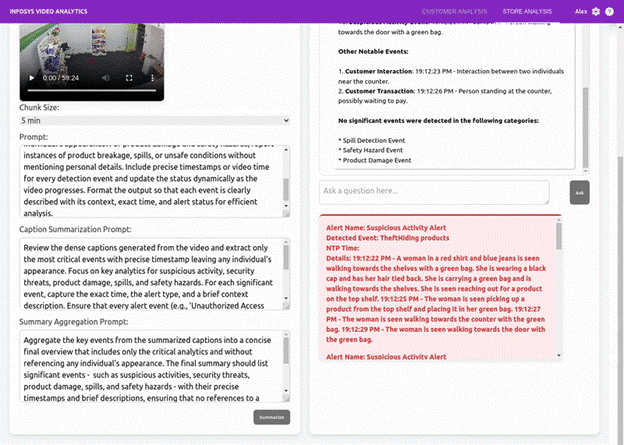
Sample Alert Triggered :The Video AI Agent processes video data to generate actionable insights. Below are key capabilities along with snapshots:
- Summarization Output
Generates a concise summary of the video, capturing key events, objects, and actions. - Question-Answer (Q&A) Output & Alerts-Event Detection
Retrieves context-aware responses from video data based on user queries.
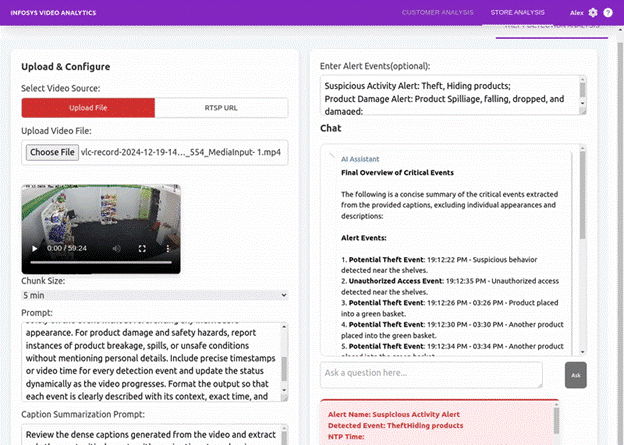
&
Triggers real-time alerts for security threats, low stock, or safety hazards.