Introduction
Retail environments are dynamic and require intelligent security systems to maintain safety and prevent theft. Traditional IP camera systems generate vast amounts of data but fail to provide actionable insights. Video AI Agent addresses this challenge by leveraging AI to transform raw video feeds into real-time, searchable intelligence.
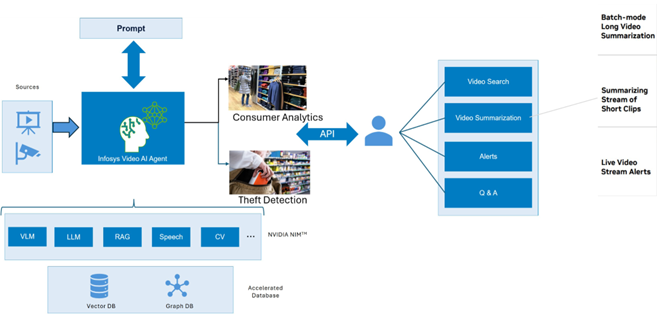
Infosys Video Analytics – Part of Infosys Topaz
Infosys Video Analytics, part of Infosys Topaz, is an enterprise-ready solution designed to enable the development of Vision AI models for product detection and other retail applications. This platform helps retailers automate operations and deploy AI-driven insights to enhance security, optimize inventory management, reduce reaction times, and improve customer experiences. Built on NVIDIA(r) AI Blueprint for video search and summarization (VSS) from NVIDIA Metropolis, Infosys Video Analytics enhances video intelligence capabilities for real-world scalability.

Classical Vision Models vs. Vision Language Models (VLMs)
One of the key technologies underlying Video AI Agent is the vision AI model. Traditional computer vision models rely on handcrafted features and require domain-specific training data to detect objects or anomalies. Such models often struggle with variations in lighting, occlusions, and complex retail environments.
In contrast, VLMs leverage multimodal learning, allowing them to understand both visual and textual context. This enhances their ability to:
- Recognize objects in diverse conditions without extensive retraining.
- Generate detailed, natural-language descriptions of scenes.
- Reduce data annotation requirements, leveraging self-supervised learning for fine-tuning.
By leveraging large-scale datasets, VLMs outperform classical models, enabling adaptive, real-time decision-making in retail applications.
Video AI Agent Architecture Overview
The Video AI Agent is built around two main pipelines:
Data Ingestion and Processing Pipeline
-
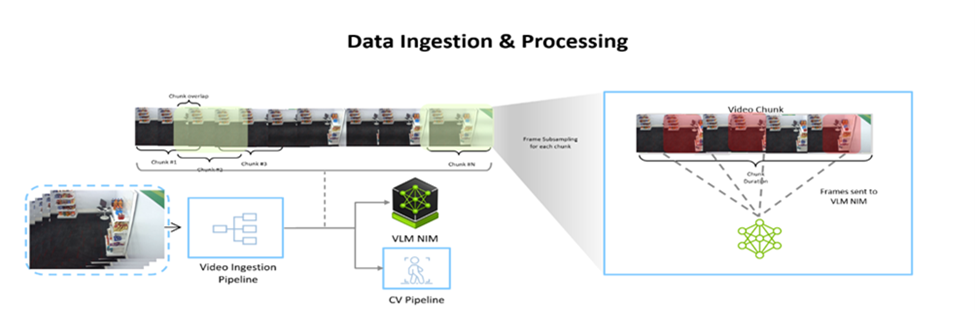
Chunk-Based Video Processing:
- Videos, whether live or recorded,are segmented into small chunks (typically seconds to minutes) due to the limited number of frames a VLM can accept. The length of these segments can be customized based on the activity and duration of the video.
- Example: If a 30-second video is split into one second chunk sizes, and if a VLM can take 10 frames from each chunk, the total number of frames would be reduced from 900 frames to 30 chunks * 10 frames = 300 key representative frames across multiple Vision Language Model (VLM) calls.
-
Parallel Processing Across GPUs:
- Chunks are processed concurrently on multiple GPUs (e.g., 8 x NVIDIA H100 Tensor Core GPUs), ensuring rapid and scalable analysis.
-
Embedding Generation and Captioning:
- For each chunk, deep video embeddings are generated and passed to advanced VLMs (e.g., VILA 1.5, GPT-4o, and custom models) for captioning.
- Generated captions, combined with metadata (timestamps, camera ID, etc.), are used in subsequent analysis.
-
Data Transfer to Retrieval Pipeline:
- Structured data from the ingestion pipeline is stored in databases optimized for fast retrieval.
Retrieval Pipeline
-
Indexing and Storage:
- Captions and metadata are stored in vector and graph databases, supporting both fast retrieval and context-aware queries.
-
Context-Aware RAG (CA-RAG):
- Summarization: Uses recursive “Refine” techniques for live streams or a two-stage “Batch” process for longer videos.
- Question & Answer (Q&A): Integrates with databases (e.g., Milvus DB/and Neo4j) and leverages advanced LLM tool calling to extract precise, context-rich answers from video data.
- Alerts: Event-based triggers notify managers in real time upon detecting suspicious or unsafe activities.
Architecture
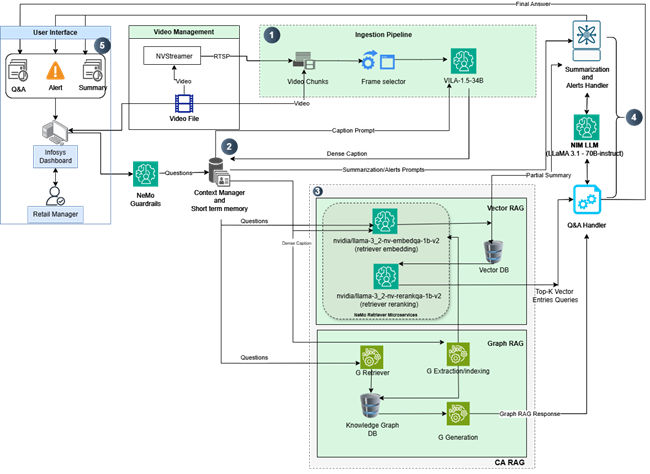
NVIDIA NIM Microservices Used:
- LLM: llama-3.1-70b-instruct
- VLM: vila-1.5-34b
- NeMo™ Retriever Reranking: llama-3.2-nv-rerankqa-1b-v2
- NeMo™ Retriever Embedding: llama-3.2-nv-embedqa-1b-v2
Hardware Used:
- 8 x NVIDIA H100 GPUs (80GB each)
- 256+ GB System Memory
- High-speed NVMe storage for rapid data access
Software Used:
- OS: Ubuntu 22.04+
- NVIDIA Driver: v535.161.08+
- CUDA(r): 12.2+
- Container Orchestration: Kubernetes v1.31.2, NVIDIA GPU Operator v23.9, cHelm v3.x
- NGC(™) API Key: For accessing NVIDIA container registry
Implementation Workflow
-
Data Ingestion & Dense Captioning
- Video streams are chunked and processed in parallel, converting frames into embeddings.
- The fine-tuned model generates frame-level captions, capturing product details and timestamps.
-
Alert Aggregation
- Alerts triggered by low stock or safety hazards are compiled into a searchable vector database.
-
Actionable Insights:
- Retail managers receive real-time notifications, and historical data assists in long-term inventory strategy planning.
Author
Apoorv Mishra, Senior Consultant, Infosys









