Scaling Cyber Defense AI: Embedding Compression for High-Volume Threat Retrieval
The next frontier in Generative and Agentic AI for cybersecurity is not model size — it’s retrieval scale. As enterprises adopt Retrieval-Augmented Generation (RAG) pipelines for incident analysis, threat hunting, and forensic automation, embedding indices now span terabytes of data across logs, advisories, and telemetry.
A recent open-source research initiative introduced CoRECT (Compression and Retrieval Evaluation for Compact Transformers), a framework that evaluates embedding compression techniques at scale. The findings reveal that compressed embeddings can reduce storage and compute load by up to 80%, while maintaining high retrieval fidelity.
For cyber defence, this represents a game-changer — enabling faster retrievals, lower infrastructure cost, and greener AI operations — all without compromising detection accuracy.
The Hidden Problem: AI Defence Systems Are Drowning in Their Own Context
Modern SOCs and cyber-defence platforms ingest enormous data streams:
- Security logs from SIEMs and cloud telemetry
- Threat intelligence feeds (MITRE, ATT&CK, CAPE, CVE advisories)
- Alerts, reports, and analyst notes
When these are converted into embeddings for semantic search or GenAI reasoning, data volume explodes. A single month’s worth of logs can exceed a billion vector entries — demanding terabytes of memory and distributed vector databases (FAISS, Milvus, Pinecone). This not only inflates cloud cost and latency but also limits how quickly analysts can query or correlate signals during incidents.
Research Spotlight — Compact Embeddings Without Losing Precision
The CoRECT framework evaluates multiple embedding compression techniques, including:
- Dimensionality reduction (PCA, autoencoders)
- Transformer encoder pruning
- Product quantization (PQ, OPQ)
- Low-bit quantization (INT8 / INT4)
In experiments, applying product quantization with adaptive codebooks reduced storage footprint by ~80%, with only 1–2% accuracy loss. This makes it feasible to scale RAG-based threat retrieval systems without compute expansion.
Applying Embedding Compression to Cyber Defense
Use Case — Threat Intelligence Retrieval
A SOC storing 200 million embeddings for:
- MITRE ATT&CK TTPs
- Malware behavior signatures
- Incident playbooks
- Log-derived entities
Each 768-dimension float32 vector consumes 3 TB total. Compression (e.g., PCA → 256 dims, PQ-8×8 INT8) can cut storage to ~400 GB — while maintaining nearly identical recall.
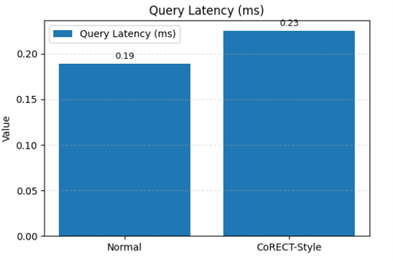
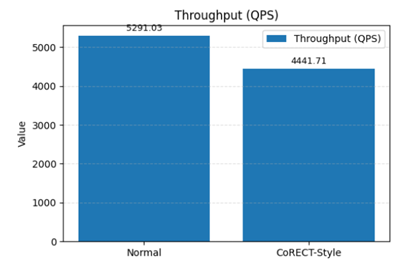
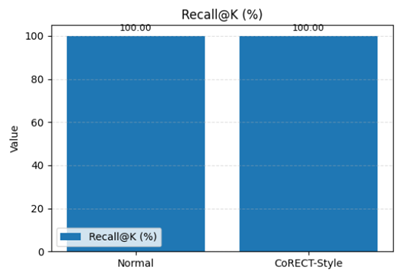
Query Latency and Throughput
Below is a live benchmark comparing Normal (Uncompressed) vs CoRECT-Style (Compressed) embeddings. The benchmark was implemented and executed in a Google Colab notebook (see link below).
Performance Summary
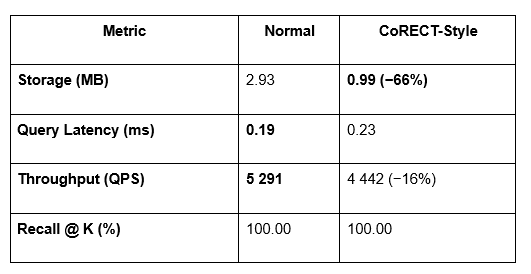
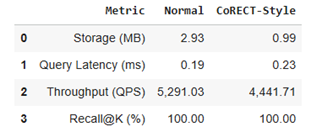
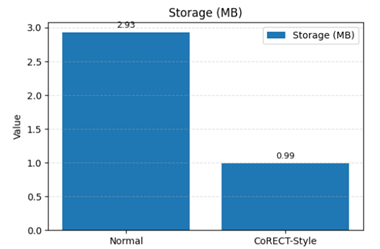
Note: the ~66% storage reduction with 100% Recall. The ~16% reduction in throughput (QPS) is an expected trade-off, making this solution ideal for[AS1] [AS2] use cases where storage cost and scale are critical, and query latency is not the primary constraint.
[AS1]Newly added
[AS2]
Live Benchmark Results
Overall Comparison
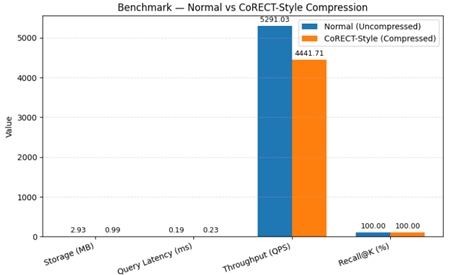
Storage Reduction (~66%)
Query Latency (ms)
Throughput (QPS)
Recall @ K (%)
Source Code & Benchmark Execution:
- Colab Notebook: https://colab.research.google.com/drive/1TbGy92zZl7ruRIzX_eJZKaOg6pdbvuAi?usp=sharing
- GitHub Repository: https://github.com/ameya/Benchmark-Normal_vs_CoRECT_framework
Implementation Blueprint
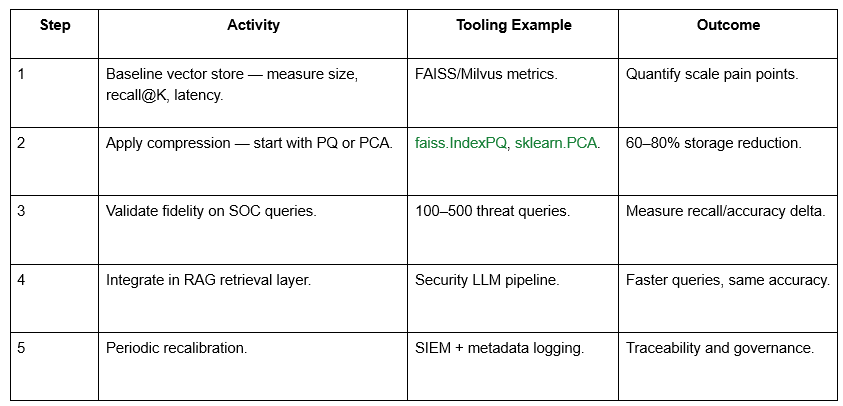
Security & Governance Perspective
Embedding compression introduces new governance considerations:
- Integrity: Add vector checksums to detect corruption/tampering.
- Explainability: Log PCA and PQ transformation metadata.
- Versioning: Maintain model + compression schema mapping.
- Confidentiality: Apply same encryption/ABAC to compressed vectors.
Thus, compression enhances both operational efficiency and governance compliance.
Environmental & Cost Impact
- 80% storage reduction = direct cloud cost savings
- Lower CPU/GPU search load = smaller carbon footprint
- Increased throughput = longer log retention & faster detection
Embedding compression supports sustainable AI operations aligned with enterprise ESG goals.
Strategic Next Steps for CISOs & AI Architects
- Pilot compression in one high-volume use case (e.g., log correlation).
- Add compression telemetry to AI observability dashboards.
- Classify embeddings as managed data assets.
- Institutionalize compression audits in SOC optimization cycles.
Conclusion
As cyber threats multiply, scaling AI defence is no longer about larger models — it’s about smarter data representation.
Embedding compression, validated through CoRECT and replicated in open benchmarks, offers a pragmatic route to faster, leaner, and greener cybersecurity AI.
By adopting these methods, SOCs can handle petabyte-scale threat data without increasing cost — transforming reactive defence into an intelligent, continuously learning cyber fabric.
References
CoRECT: A Framework for Evaluating Embedding Compression Techniques
Open-Source Vector Compression Benchmarks – Hugging Face Research
GitHub: Benchmark-Normal_vs_CoRECT_framework
Google Colab: CoRECT-Style Compression Benchmark
Security Boulevard – October 2025 Data Breach Report









