AI Agents are rapidly becoming the defining software paradigm of this decade. Their ability to not only execute tasks but dynamically decide what to do next in real time is a key reason for their widespread popularity. In record time they have moved from research labs to production systems.
We are deploying AI Agents at scale allowing them to write code, orchestrate APIs, take decisions in critical enterprise workflows, all without a standardized framework to assess them. In fact, we can argue that Agentic AI may be the first mainstream computing paradigm to be widely adopted before rigorous QA methodologies have been properly determined
The Problem with QA in Agentic Landscape
Every major shift in computing had a QA lag, be it web applications, mobile apps or Machine Learning, but the gap we are seeing now is fundamentally different.
Why? Because for decades Quality in Software Engineering operated on certain assumptions
1. Determinism: Same input in the same state produces the same output
2. Bounded Execution: Programs follow predictable execution paths
3. Binary Outcomes: The system either works or it fails
4. Isolated Execution: The system runs without any external interventions
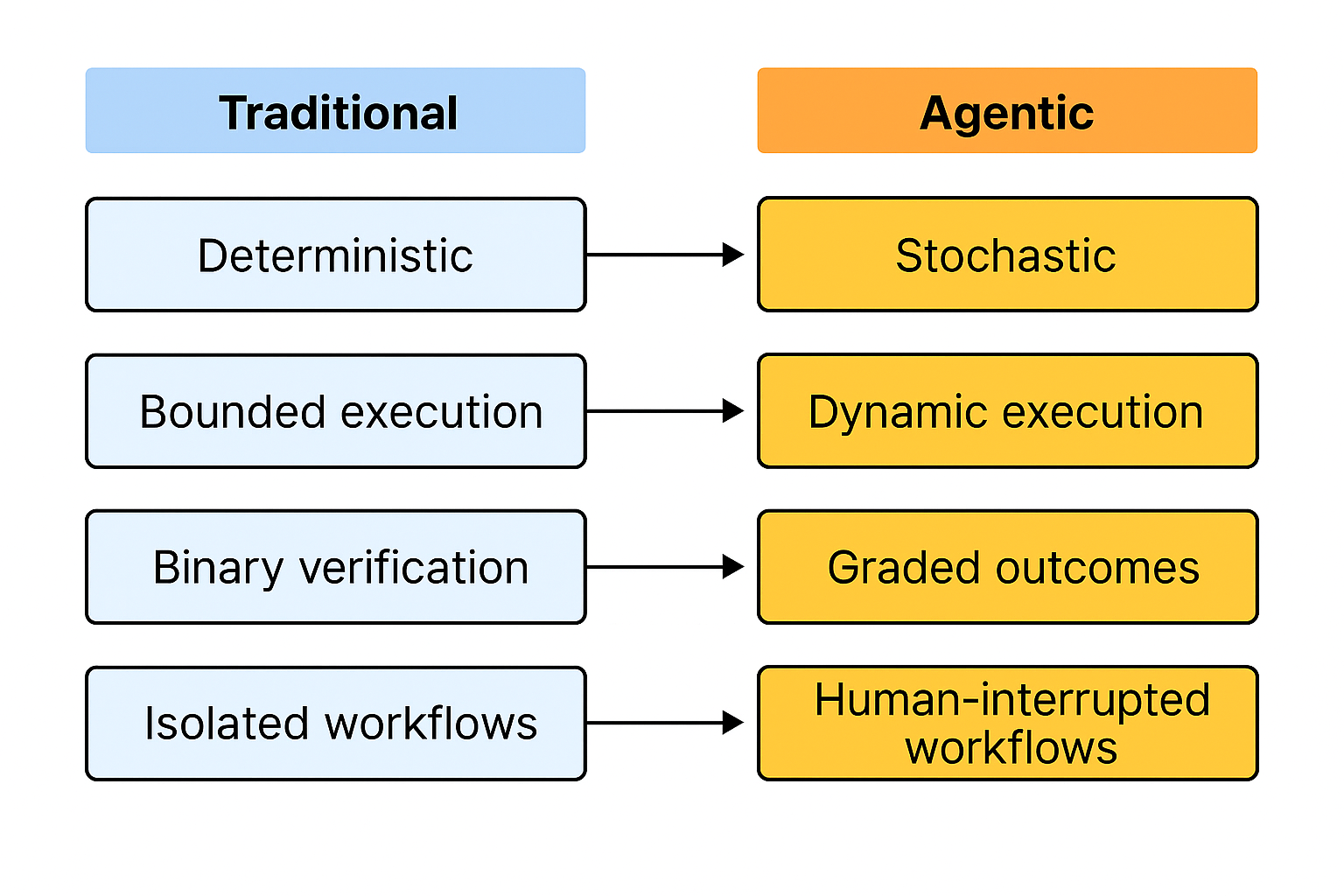
Agentic AI violates all 4 assumptions simultaneously.
· Agents are built on LLMs which by nature are stochastic, the same input may give varying outputs
· Agents work across many steps and can change the execution paths in case of issues or failures
· Agent responses cannot be judged as binaries. They can be graded in multiple ways, partially correct, suboptimal, insufficient, unsafe, etc.
· Humans can be part of Agent workflows to interrupt, override or correct Agents introducing new paths that the QA hadn’t considered before.
Unsafe Decision Making
Perhaps we are not ready to seriously ask what the impact would be when agentic systems fail. Or maybe we believe since agents are still in their early stages and contained enough, the consequences would still be manageable.
Whatever the reason, industry has been remarkably comfortable deploying autonomous systems at scale without accounting for what failures could cost.
Unlike a human employee who would pause when something feels wrong, an agent can keep going. As Agents become more decision-makers rather than merely decision-supporters the financial exposure is real. Without proper monitoring Agents can enter loops, burn through resources & make consequential decisions all without a single alert being raised.
The most cited example for this is the case of Air Canada which used an AI Assistants for customer support. The chatbot promised a discount that was not actually available & when the customer tried to claim it the company argued it was not responsible for the chatbot’s mistake, but a court ruled that businesses are responsible for what their AI assistants do
The question is not whether Agents will fail. They might as any system could. The question is whether we have done the work to understand how they failed & what the cost will be when they do
Existing Benchmarks in Agent Evaluation
Although there are no agreed standards for evaluating AI agents the approaches that exist today can be grouped by what they actually test:
i. Tool use and API invocation: Can the agent find the right tool, call it correctly and pass the right inputs? This is the most developed area of evaluation today, largely because it is the easiest to measure. Either the tool was called correctly, or it was not.
ii. Multi-step Task Completion: Can the agent stay on track across a long, complex task without losing the context?
iii. Safety: Will the agent stay within its boundaries when pushed? This tests whether the agents can resist attempts to manipulate its work which is critically important for production workflows
iv. Cost, Latency & Efficiency: Can the Agent do its job at a speed and cost that makes the deployment viable? This barely exists as a formal evaluation discipline right now despite it being one of the first questions any organization needs to ask before going to production
How We Can Improve Evaluation
The goal of evaluating agents should not be to prove they work, but to understand where it breaks. Currently we are asking whether the agent has reached its destination, which is a start but is nowhere enough
· Did the Agent take the most Optimal Route? An agent consuming far more resources than necessary is not production ready.
· Can the Agent handle Roadblocks? Good evaluation strategies introduce conditions where the Agent must recognize something has gone wrong to test its ability to find an alternate route and more critically if it knows when to stop and ask for assistance instead of taking imaginary paths
· Did the agent stop at the right checkpoints? Reaching the goal optimally is not enough if the agent skipped certain checkpoints it was required to make
· Can the Agent justify the path it took? Whether the agent took the right path or not it should be able to provide its reasoning. Without this there is no way to audit, improve or trust the system at scale
Who Should Own QA in Agentic AI?
The ownership question is still unsettled because when something goes wrong in an agentic system, accountability is fragmented across model provider, the orchestration platform and the enterprise deployer

Ownership must be layered.
Model providers own the foundational behavior of the system. How it reasons, where it refuses, hallucination rates & how reliably the model follows instructions. This is their QA responsibility
Orchestration platforms like Langgraph, Google ADK own runtime constraints, context storage, and tool call validations. Failures at this layer including dropped context, incorrect tool calls are the platform’s responsibility
That said, it is the deploying organizations that own everything from use case definition to human oversight and outcomes. They decide what authority the agent has, which systems it can access and under what conditions human oversight is needed. This makes the deploying organization the primary accountability holder regardless of where in the stack the error originated.
Where Do We Go From Here?
Unlike other computing paradigms agents are far more consequential due to their decision-making & action-taking abilities. The growing gap between deployment and rigorous evaluation is concerning. While significant progress has been made in creating more realistic, dynamic, and challenging benchmarks, critical gaps remain, particularly in the areas of safety, fine-grained evaluation, and cost-efficiency. The strategies discussed here are arguably the bare minimum. This field will go much further and better, more rigorous standards will emerge as researchers and practitioners engage with the problem.
References
1. https://www.connectedpapers.com/main/1ac6b0d31ad221a6fb6b505585ccdb107d8b92cb/arxiv
2. LLM & AI Agent Evals Platform: Continuously improve agents








