How Vision-Language-Action models are collapsing decades of modular AMR engineering into a single learned system — and what that means for warehouses, hospitals, and beyond.
I. The Stack Problem
For decades, autonomous mobile robots have been built around a familiar blueprint: a pipeline of discrete modules, each responsible for a narrow slice of the problem. The robot perceives its surroundings through sensors, builds a map, localises itself within it, plans a path, and executes that path with a low-level motion controller. Each stage hands a structured output to the next. Each stage also introduces assumptions — and assumptions fail.
In a controlled warehouse with flat floors, fixed shelving, and predictable human behaviour, this architecture performs admirably. But the deployment envelope of modern AMRs is expanding fast. Robots are entering hospital corridors, construction sites, retail floors, and outdoor campuses — environments that are dynamic, cluttered, semantically rich, and resistant to the kind of exhaustive up-front mapping that classical pipelines depend upon.
The failure modes are well understood by anyone who has deployed robots in the field. A perceiving module misclassifies a partially occluded object. The map drifts after a shelving unit is moved. The path planner freezes when a human steps into its costmap at an awkward angle. A rule-based behaviour tree reaches a state its authors never anticipated and stops. These are not bugs to be patched individually — they are structural consequences of the modular approach itself.
The Classical AMR Pipeline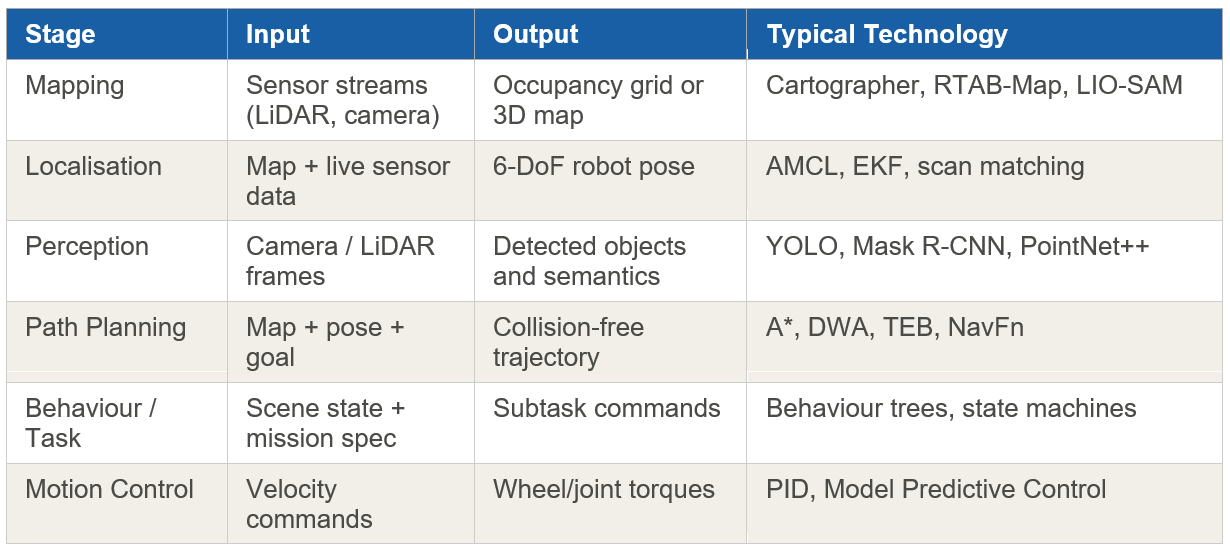
The central question now facing AMR engineers and researchers is whether this layered scaffolding can be meaningfully replaced — or restructured — by a single model that sees the environment, reasons about it in natural language, and produces grounded actions directly. That model class is known as Vision-Language-Action models, or VLAs, and their arrival in robotics is beginning to reshape how the industry thinks about robot intelligence.
II. The Classical AMR Stack in Detail
Understanding the scope of what VLAs might change requires a clear-eyed view of what the classical stack actually does — and where it reliably fails in real deployments.
Module-by-module breakdown and failure modes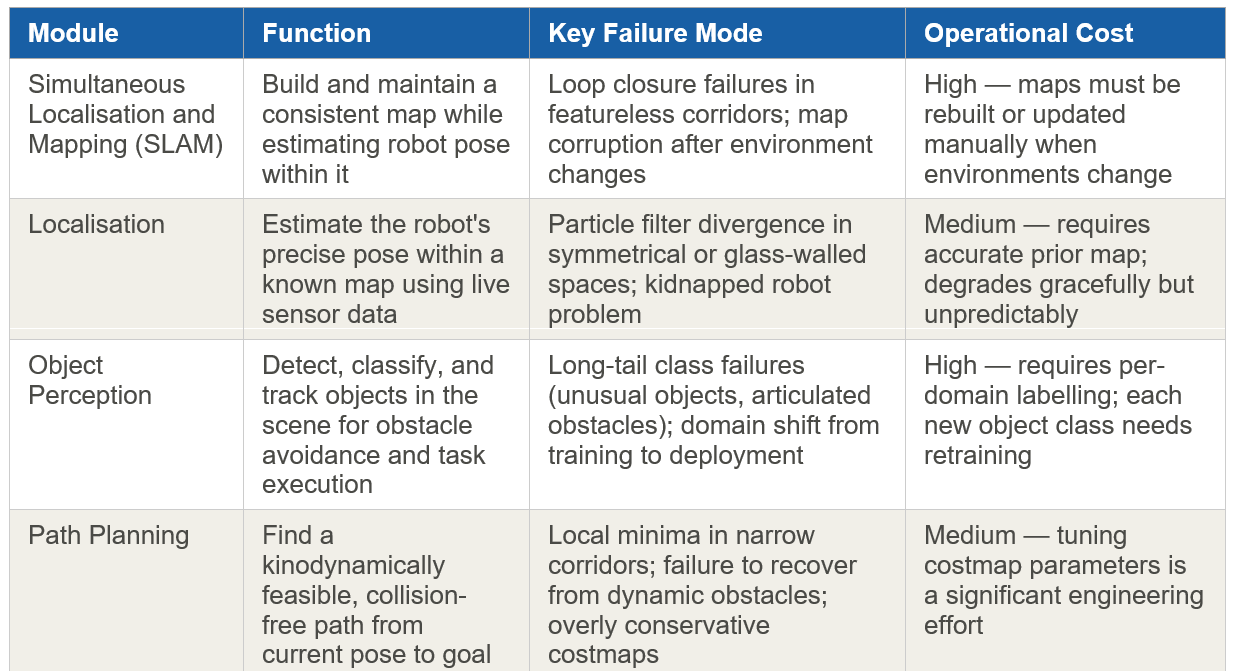

Across this stack, three systemic problems recur in production deployments. First, error compounding: a 2% localisation error feeds into planning which feeds into control, and small errors early cascade into large failures downstream. Second, the long tail: classical modules are trained and tuned on anticipated scenarios; novel situations — a spilled liquid, a collapsed box, an unexpected person lying on the floor — fall outside the distribution and produce unpredictable behaviour. Third, the knowledge bottleneck: behaviour trees and rule systems encode only what their authors anticipated; they have no mechanism for reasoning about situations they were not designed for.
III. What Are VLA Models?
A Vision-Language-Action (VLA) model is a foundation model that jointly processes visual observations from one or more cameras, natural language in the form of task instructions or scene descriptions, and produces grounded action outputs — typically joint positions, end-effector poses, base velocity commands, or higher-level navigation waypoints.
VLAs are not a single architecture but a family of approaches united by a common design principle: that visual perception, language understanding, and action generation should be trained together, in a single model, using large-scale diverse data, rather than engineered separately and interfaced through hand-crafted representations.
The Three Pillars of a VLA

The Lineage: LLMs to VLMs to VLAs
The capability trajectory that produced VLAs is worth tracing, because it explains both their strengths and their current limitations. Large language models — GPT-3, LLaMA, PaLM — demonstrated that scaling transformer pre-training on text produced models with remarkable generalisation: few-shot reasoning, instruction following, and broad world knowledge.
Vision-language models extended this to images. GPT-4V, Gemini, and LLaVA showed that a language model backbone with a vision encoder attached could reason about visual scenes — identifying objects, reading signs, understanding spatial relationships — with capabilities that rivalled or exceeded task-specific computer vision systems on many benchmarks.
VLAs added the action dimension. The key contribution of RT-2 (Brohan et al., 2023) was demonstrating that robot actions could be tokenised and treated as another output modality in a vision-language model, allowing the full generative capacity of the language backbone — including chain-of-thought reasoning, novel instruction following, and out-of-distribution generalisation — to inform physical robot behaviour. The emergent result was a robot that could execute instructions it had never encountered during robot-specific training, drawing on knowledge acquired from internet-scale pre-training.
IV. Why VLAs Are a Fit for Autonomous Mobile Robots
The structural advantages of VLAs map closely onto the structural weaknesses of the classical AMR stack identified in Section II. This alignment is not coincidental — it reflects the fact that the hardest unsolved problems in AMR deployment are fundamentally problems of generalisation and semantic understanding, which are precisely what large pre-trained models are designed to address.
Five Structural Advantages for AMR Deployments

A particularly important advantage for AMR operators is what might be called semantic graceful degradation. When a classical AMR encounters a state its behaviour tree was not designed for, it typically freezes, requests human intervention, or makes a conservative decision that may not be appropriate. A VLA-based robot has the capacity to reason about the novel situation using its pre-trained world knowledge and produce a contextually appropriate response — even if that response is simply to express uncertainty in natural language and ask for clarification.
This concludes Part 1 of our series. In the upcoming sections, we’ll build on these foundations and explore the next phases in greater detail.












